Ranking Rule Features and Values
The Feature Ranking task is a graphic visualization of the importance of attributes within a class (attribute ranking), and of the values within specific attributes (value ranking).
The task can be used with any task that generates rulesets, such as:
Hierarchical Basket Analysis (if the generated association rules are first converted into a ruleset)
Similar Items Detector (if the generated association rules are first converted into a ruleset)
Prerequisites
the required datasets have been imported into the process
a task has generated a ruleset in the process.
Procedure
Drag and drop the Feature Ranking task onto the stage.
Connect a task, which contains the ruleset you want to analyze, to the new task.
Double click the Feature Ranking task.
Configure the options described in the Feature Ranking options table below.
Feature Ranking options | |
Parameter Name | Description |
|---|---|
Percentage of training set used | The percentage of patterns considered in the plots. By default, it is 100%, but this may change if you filter data in the Query Manager pane. |
Attributes | The attributes present in the rules for each class, ordered according to the Order attributes by option. The attribute selected here will determine which attribute is displayed in the Value Ranking plot. |
Displayed relevances | You can decide whether you want to display plots that refer to:
This option is only available for nominal output values. |
Enable multi-plot | If checked, a plot is displayed for each relevance selected in the Displayed relevances option. This option is only available for nominal output values. |
Interval for output | You can select an interval of output values to be included in the Attribute Ranking plot. This option is only available for ordered output values. |
Order attributes by | You can select the criterion for sorting the list of attributes. Possible choices are by:
This option is applied to the Attribute Ranking plot. |
Order values by | You can select the criterion for sorting the values of each attribute. Possible choices are by:
This option is applied to the Value Ranking plot. |
Number of displayed attributes | Select the number of attributes you want to include in the Attribute Ranking plot. |
Number of displayed values | Select the number of attributes you want to include in the Value Ranking plot. |
Order by absolute values | If selected, relevances are ordered according to their absolute value. This is meaningful if have decided to display relative relevances which may also have negative values. |
The Query Manager panel is not displayed by default but it can be activated (or hidden) by clicking on the arrow at the bottom of the page. You can then filter the data on which feature ranking is computed.
For details on how to use the Query Manager see the Querying Data in the Data Manager page.
Results
The results of the Feature Ranking task can be viewed in two separate tabs:
The Attribute Ranking tab, where all the attributes that make up the rules according to their output class or output interval are displayed.
The plot displays the options selected in the left-hand pane, such as the number of displayed attributes and whether both output classes are represented or not.
Right-clicking the plot offers a series of operations that can be performed to change the display properties, which are described in the Customizing Plots page.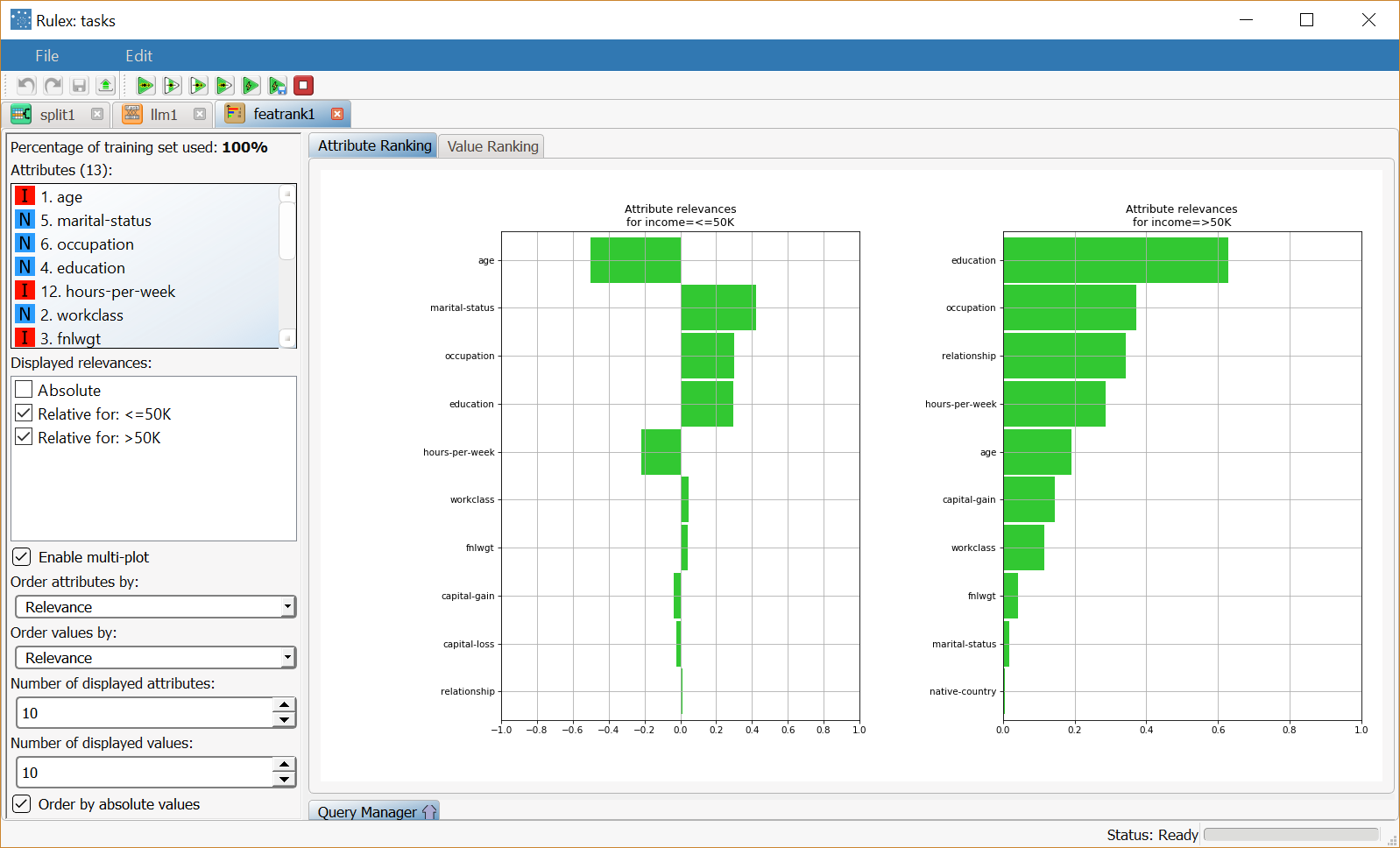
The Value Ranking tab, where the relevances of the single values of each variable are displayed. For ordered attributes the values correspond to the intervals in which the variable has been divided.
The plot displays the options selected in the left-hand pane, such as the number of displayed values and how they are ordered.
Right-clicking the plot offers a series of operations that can be performed to change the display properties, which are described in the Customizing Plots page.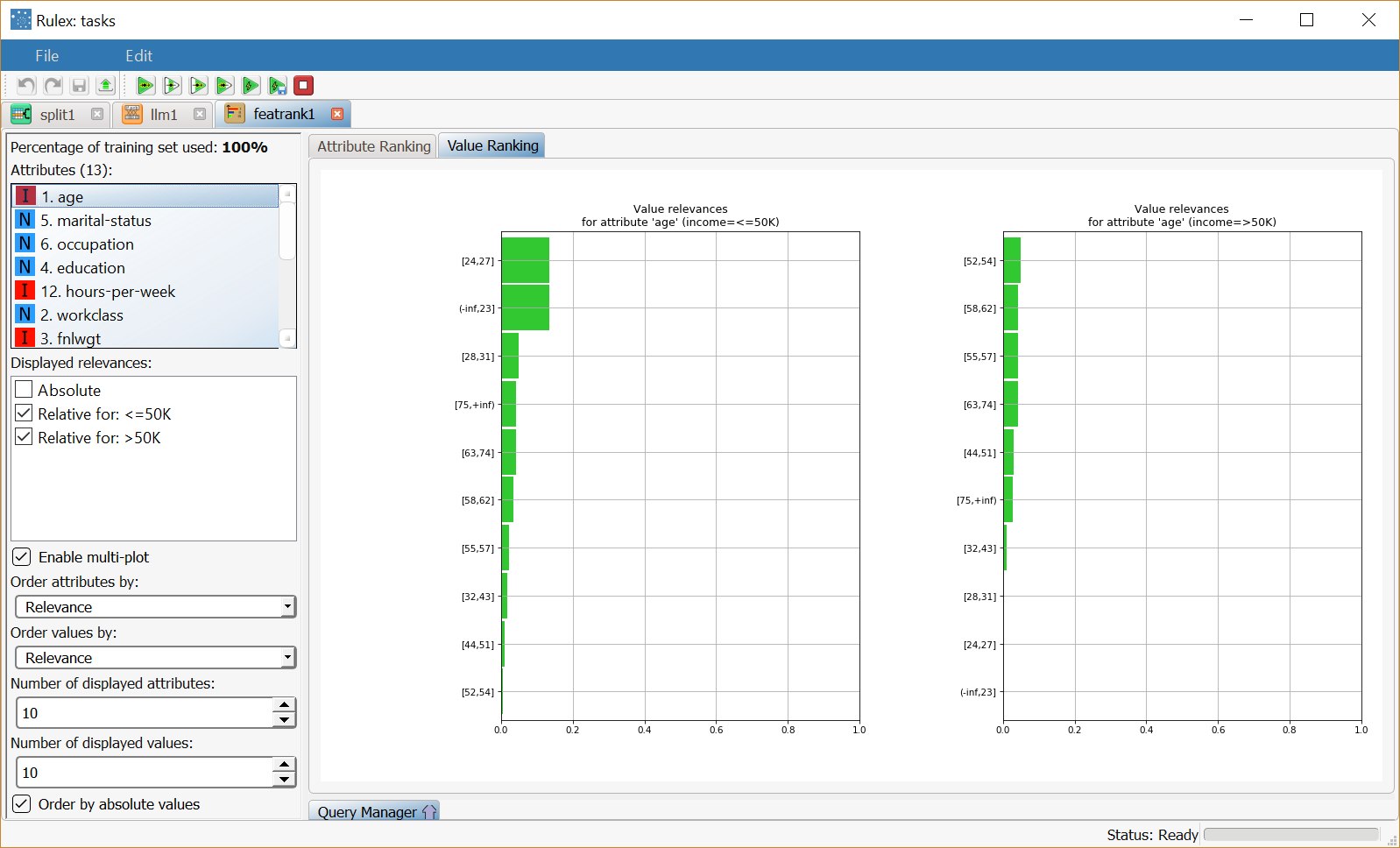
Example
The following examples are based on the Adult dataset.
Scenario data can be found in the Datasets folder in your Rulex installation.
The scenario to analyze the results of a simple classification problem based on ranges on income.
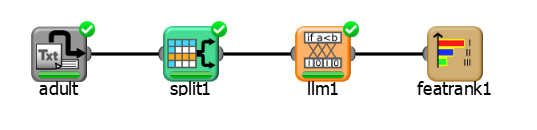
The following steps were performed:
First we import the adult dataset with an Import from Text File task.
Split the dataset into a test and training set with a Split Data task.
Generate rules from the dataset with the Classification LLM with Income as the output attribute.
Analyze the relevance of each attribute for the rules with a Feature Ranking task.
Procedure | Screenshot |
|---|---|
We have included 10 attributes in the plot. From the Attribute Ranking plot we can easily see that the education variable is the most important attribute in determining the output. | 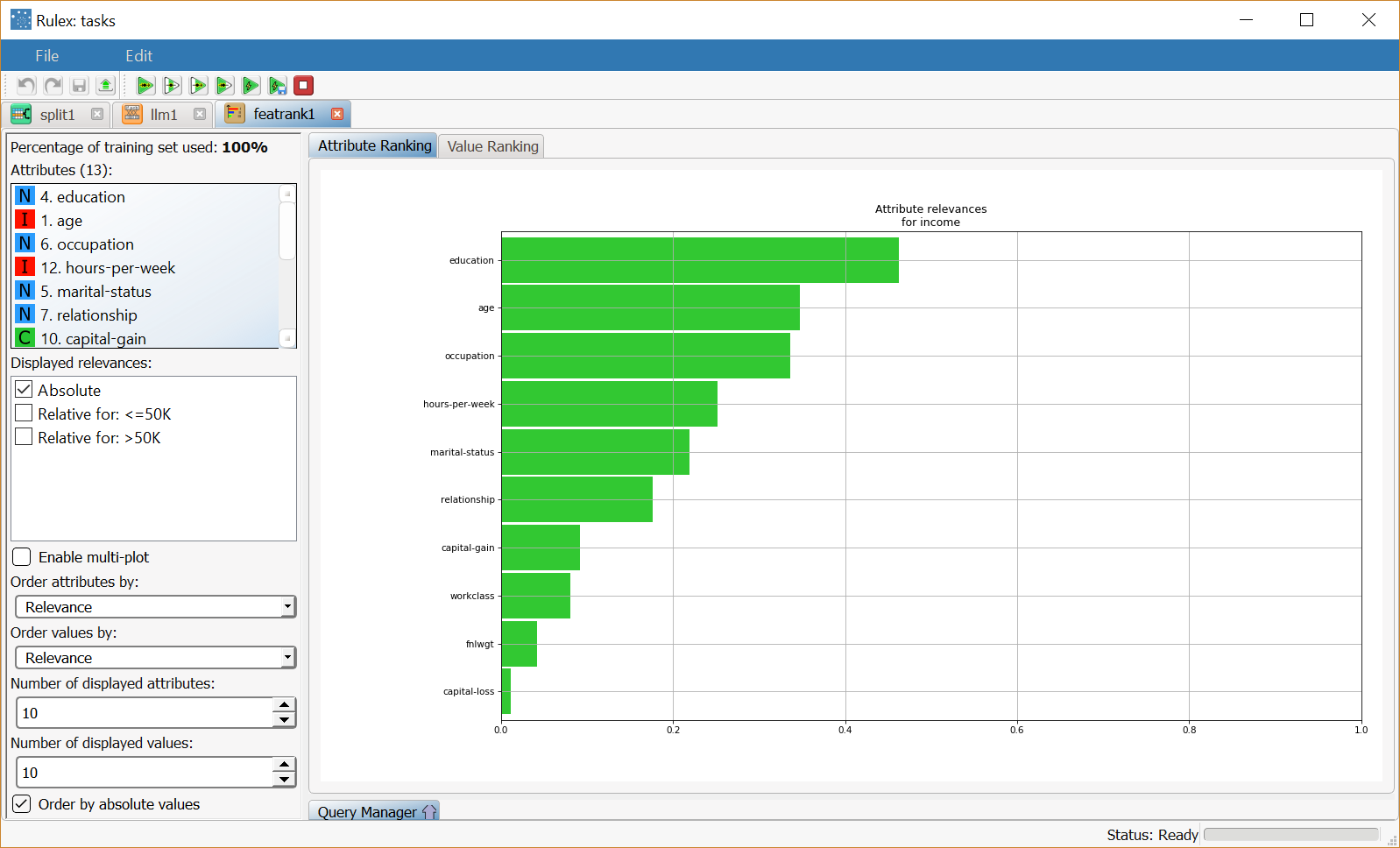 |
If we decide to display only the attributes related to an output <=50K the plot changes noticeably, and also contains negative values, indicating that the attribute is inversely correlated with that output value. If the Order by absolute values option is selected, attributes are sorted according to the absolute value of relevance. | 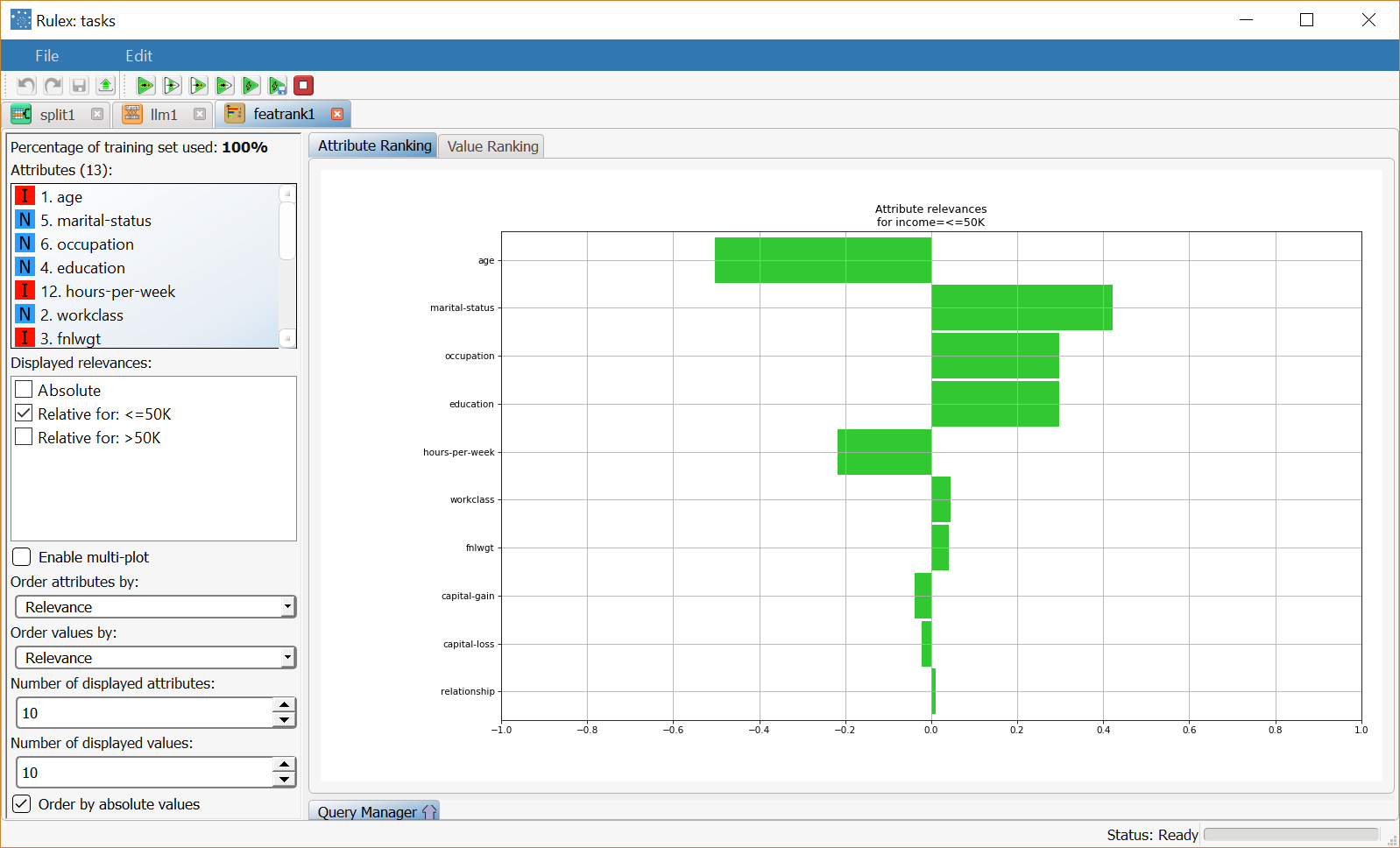 |
Clicking on the Value Ranking tab you can view the relevance of each interval, for selected attributes. In the example the relevances are displayed for the age attribute, in decreasing order of importance. | 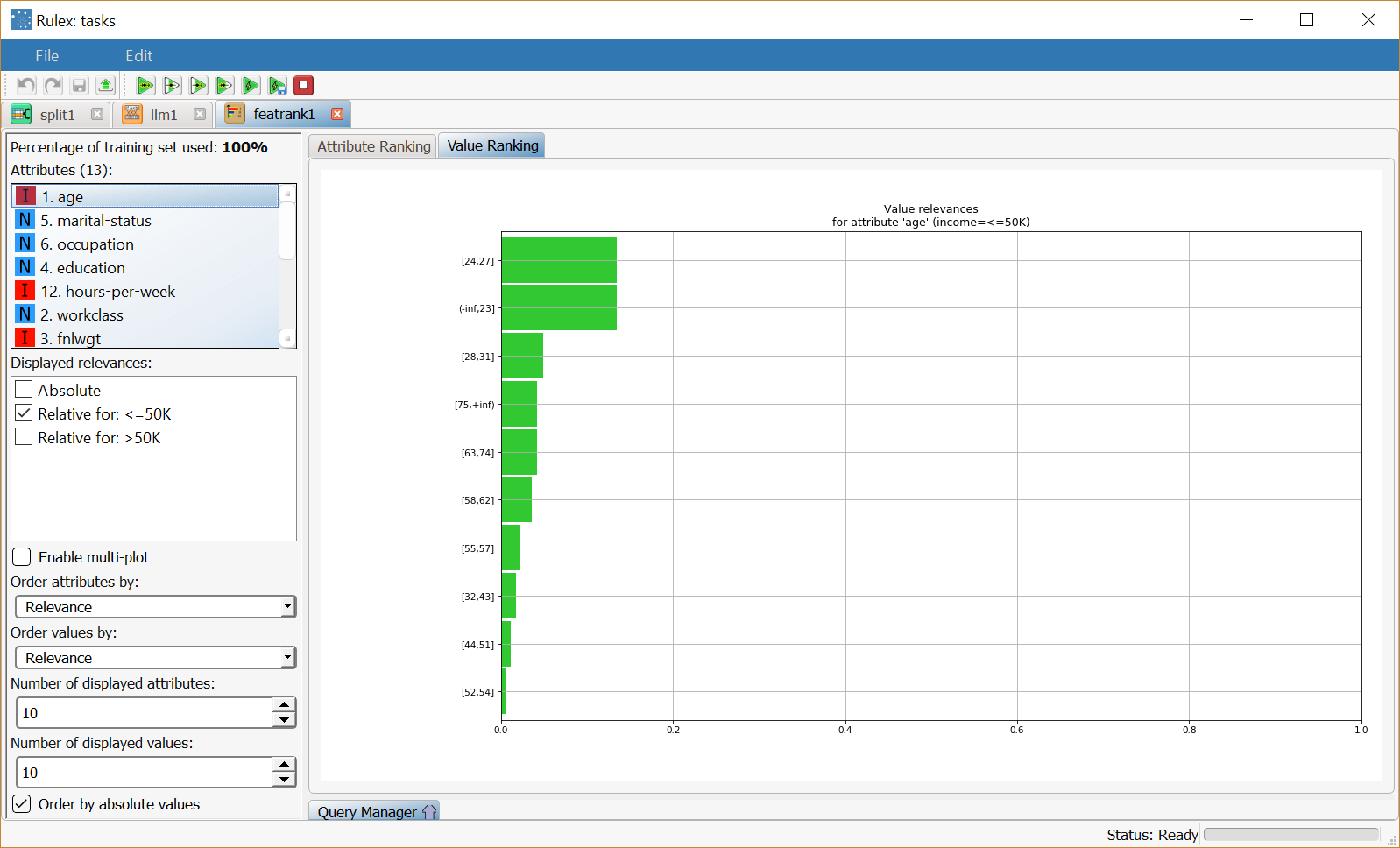 |