Analyzing Model Performance in the Confusion Matrix
The Confusion Matrix computes and visualizes the performance of any classification method.
Each column of the matrix represents the patterns in a predicted class, while each row represents the instances in an actual class.
Prerequisites
the required datasets have been imported into the process
a task with an output and a prediction column is provided as input for the task.
Procedure
Drag and drop the Confusion Matrix task onto the stage.
Connect a task, which contains the output and prediction columns, to the new task.
Double click the Confusion Matrix task. The model performance is displayed, as explained in the Results section below.
Change the output you want to display from the Output drop-down list.
Change the column of the forecast output from the Prevision list.
Change the dataset whose results you want to display from the Display matrix for drop-drop list. Possible options are Training set, Test set or All.
Select Show percentage to display the percentage in the table in parentheses.
Results
The Forecast pane displays the results in in two different matrices:
the numerical matrix represents the percentages of samples that were correctly and incorrectly predicted in a grid.
the graphical matrix represents the same information in an easy to read grid, where each column of the matrix represents the patterns in a predicted class, while each row represents the instances in an actual class:

Example
The following examples are based on the Adult dataset.
Scenario data can be found in the Datasets folder in your Rulex installation.
The scenario aims to solve a simple classification problem based on ranges on income.
We will use the Confusion Matrix block to evaluate how the forecast output differs from the actual one.
Note that the Confusion Matrix is independent from how the forecast has been generated.
The following steps were performed:
First we import the adult dataset with an Import from Text File task.
Split the dataset into a test and training set (30% - 70%)with a Split Data task.
Generate rules from the dataset with the Classification LLM.
Apply the rules to the dataset with an Apply Model task.
View the performance of the model with a Confusion Matrix task.
Procedure | Screenshot |
|---|---|
After importing the adult dataset with the Import from Text File task, split the dataset into test and training sets (20% test, 20% validation and 60% training) with the Split Data task. | 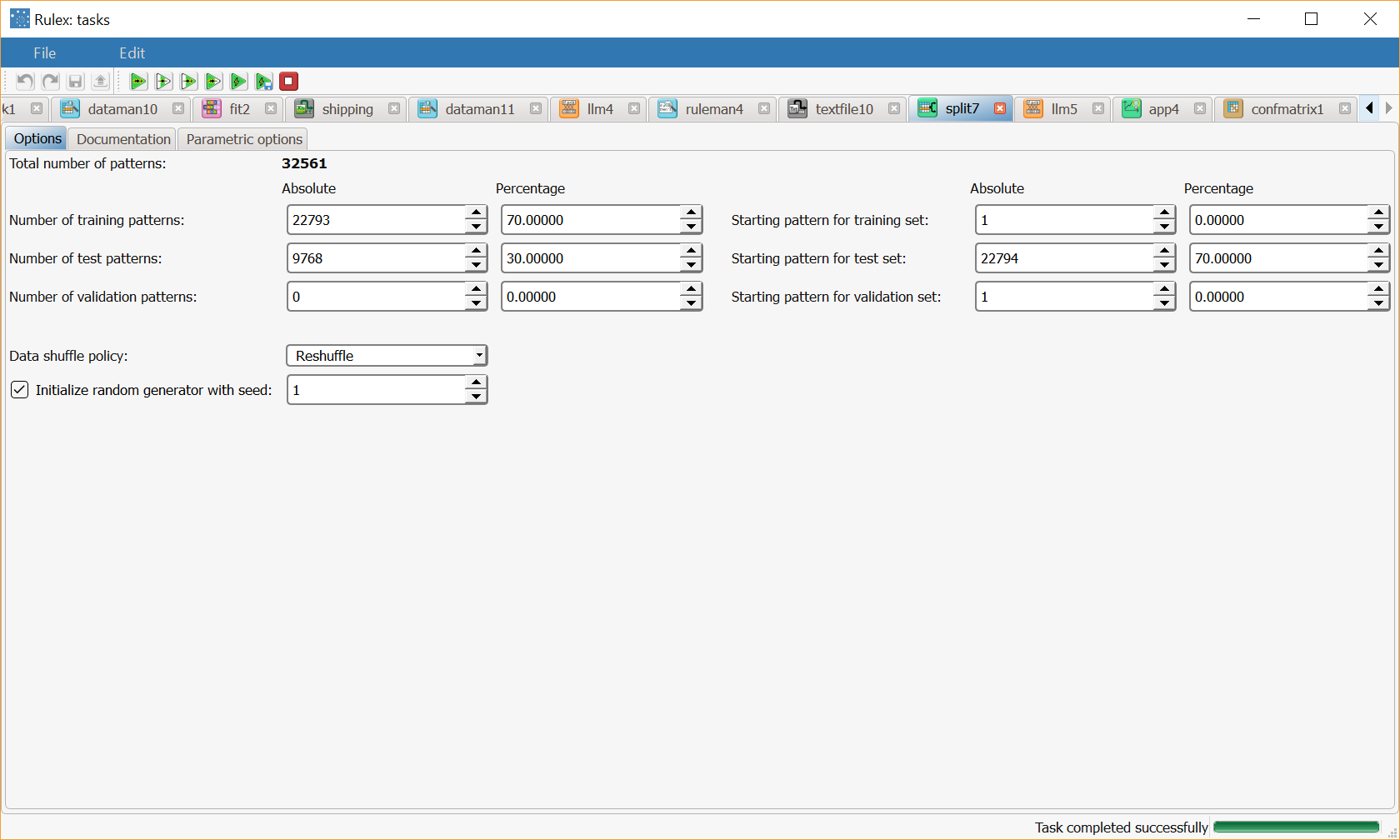 |
Add a Logic Learning Machine classification task to the process, and drag and drop the income attribute onto the Output attributes list. Save and compute the task. | 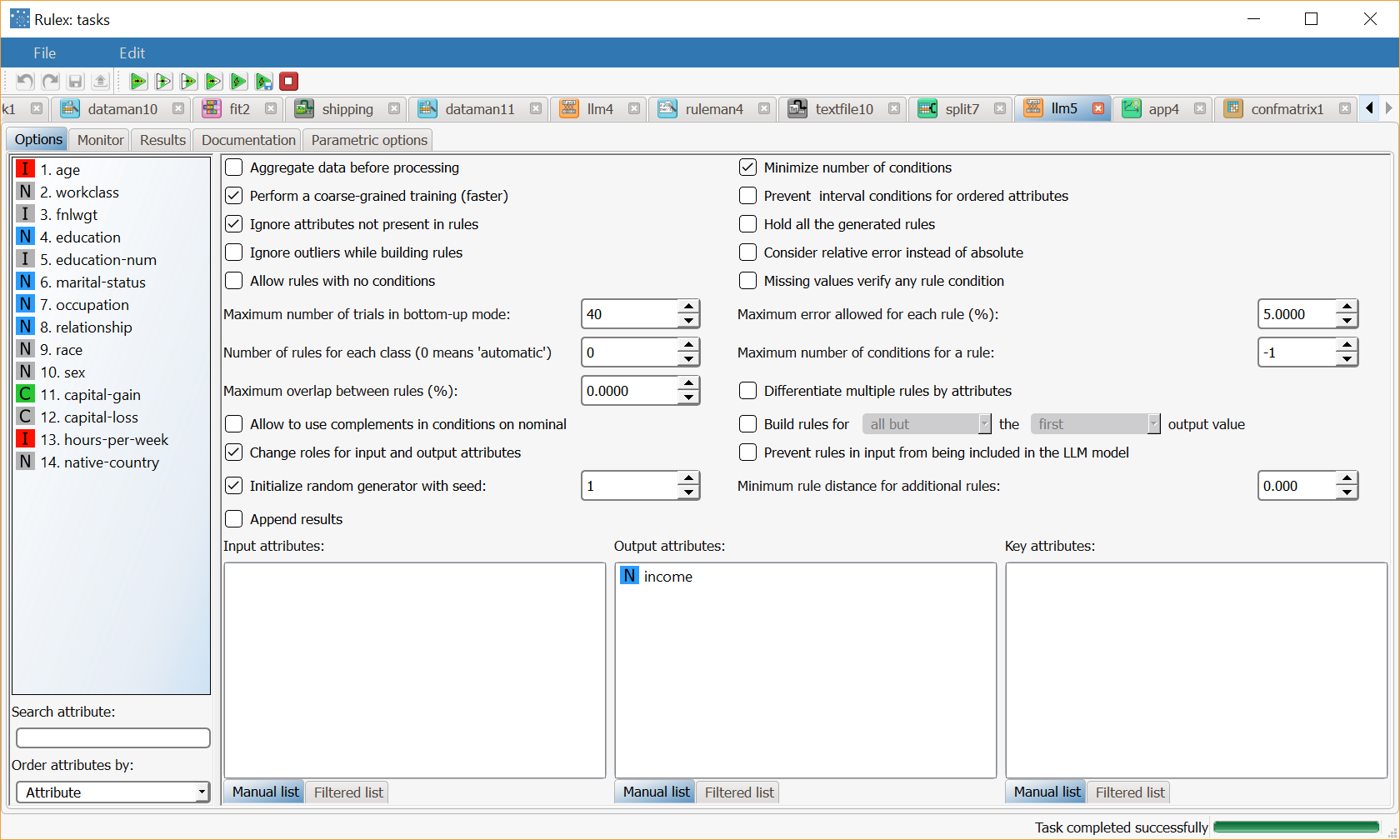 |
Add an Apply Model task to the process and compute with default settings. | 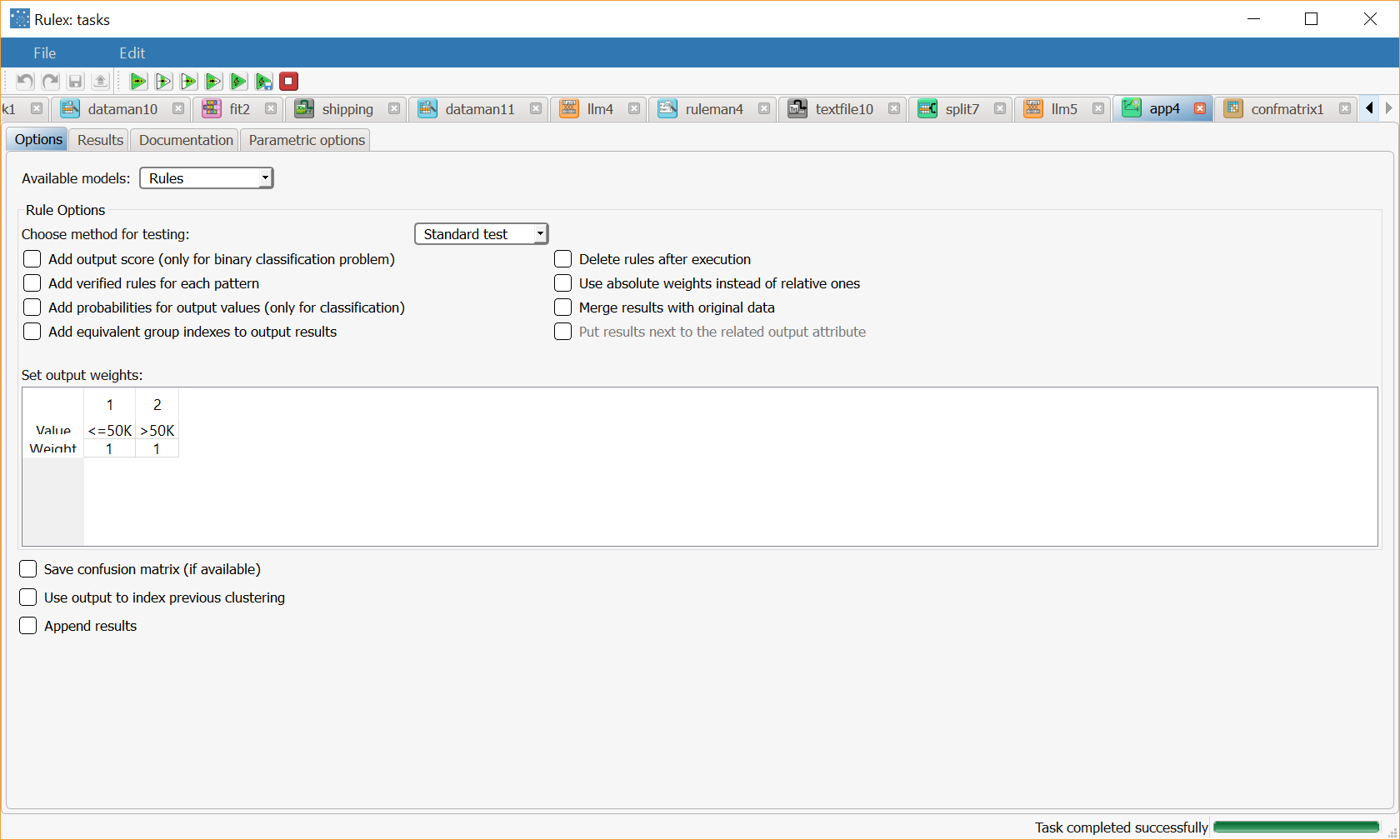 |
The confusion matrix for the test set shows that the majority of errors derive from misclassification among class >50K and <=50K. In other words there are few cases of class <=50K classified as >50K but many examples of class >50K classified as <=50K. Note that in a two-class problem, the confusion matrix may appear trivial, but if more classes are present the information contained in the matrix may help understand the studied phenomenon and improve the classification accuracy. | 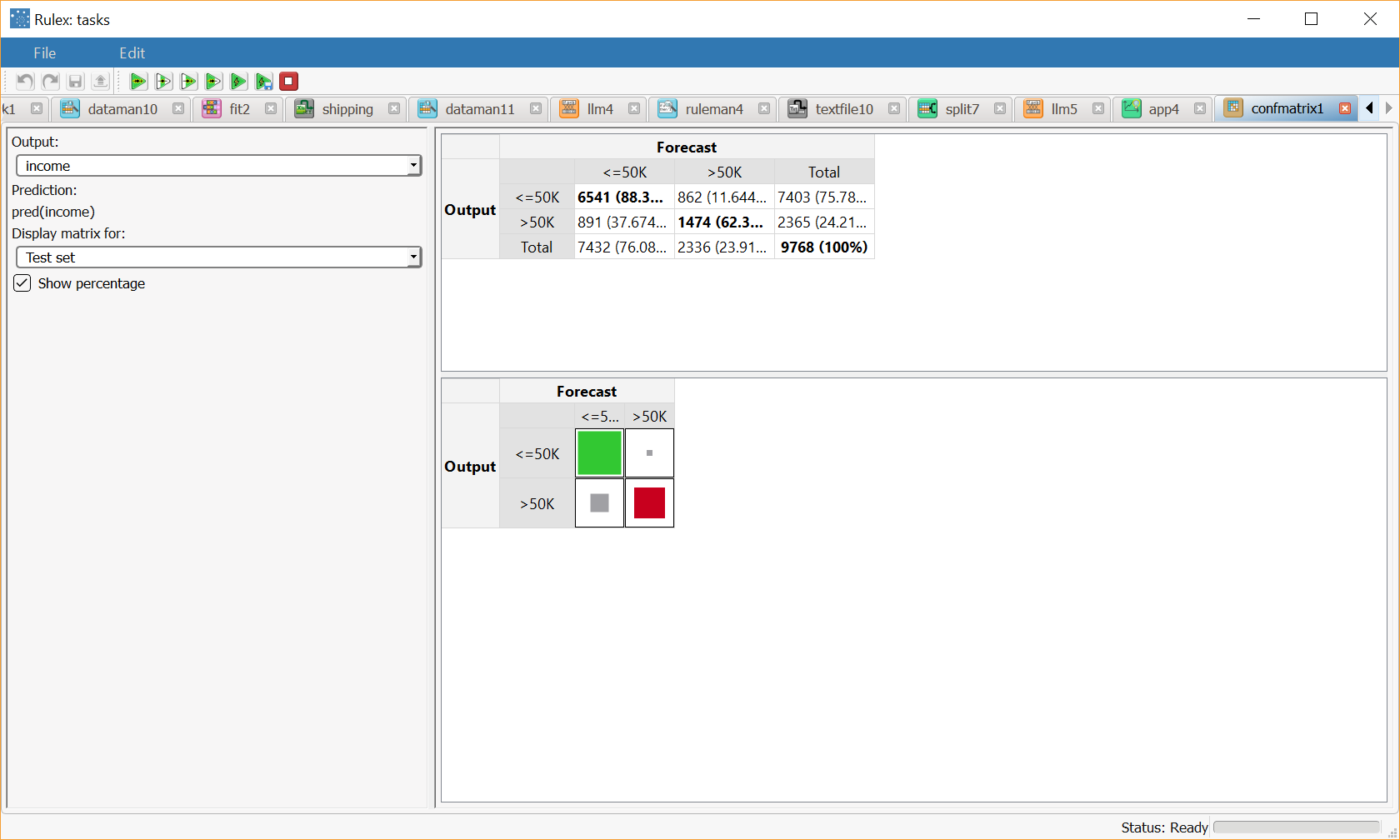 |