Grouping Data in the Query Manager
Grouping consists in identifying subsets of cases having the same value of a certain variable or set of variables.
Grouping can be coupled with Apply operations (see Applying Operations on Data in the Query Manager) in order to apply operators on each group individually.
There are two ways to show groups in Rulex, and a corresponding icon is displayed in the header of the Group column:
Group Mode | Description | Icon |
|---|---|---|
Contracted | Each group is shown as a single record, namely the first one (i.e. that having the lowest value of row index) |  |
Expanded | All the rows are shown, divided in groups. |  |
Changes you make can be committed run-time or on request.
Procedure
Drag and drop the attribute you want to group by onto any cell of the Group column: when the attribute is dropped on the Group column the subdivision in groups in automatically computed. More than one attribute at a time can be selected.
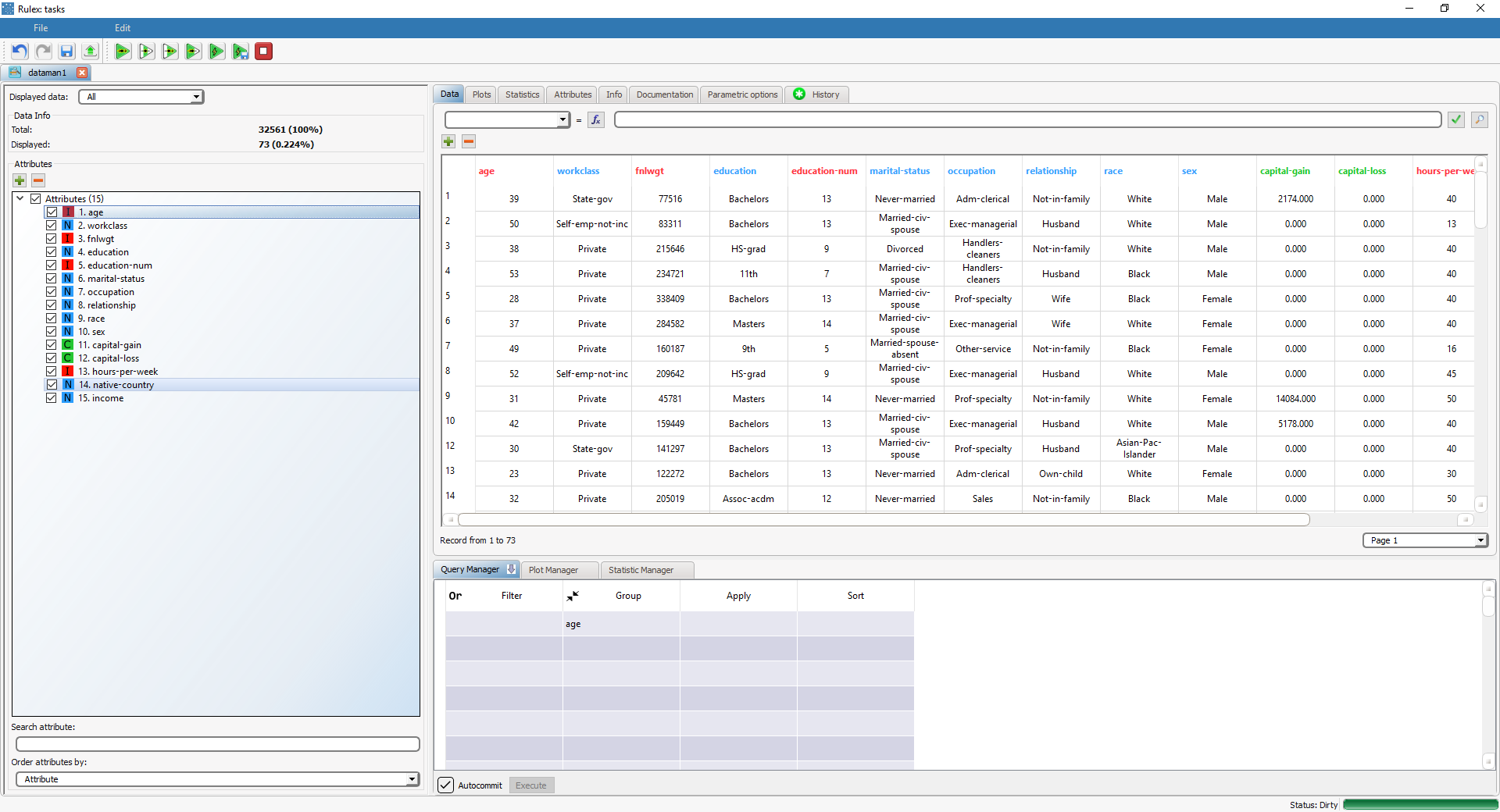
To toggle between the contracted and expanded grouping mode, right-click one of the attributes in the Group column, and select/deselect Expand.
Save and compute the task.
Example
The following example is based on the Adult dataset.
Sample Datasets
Scenario data can be found in the Datasets folder in your Rulex installation.
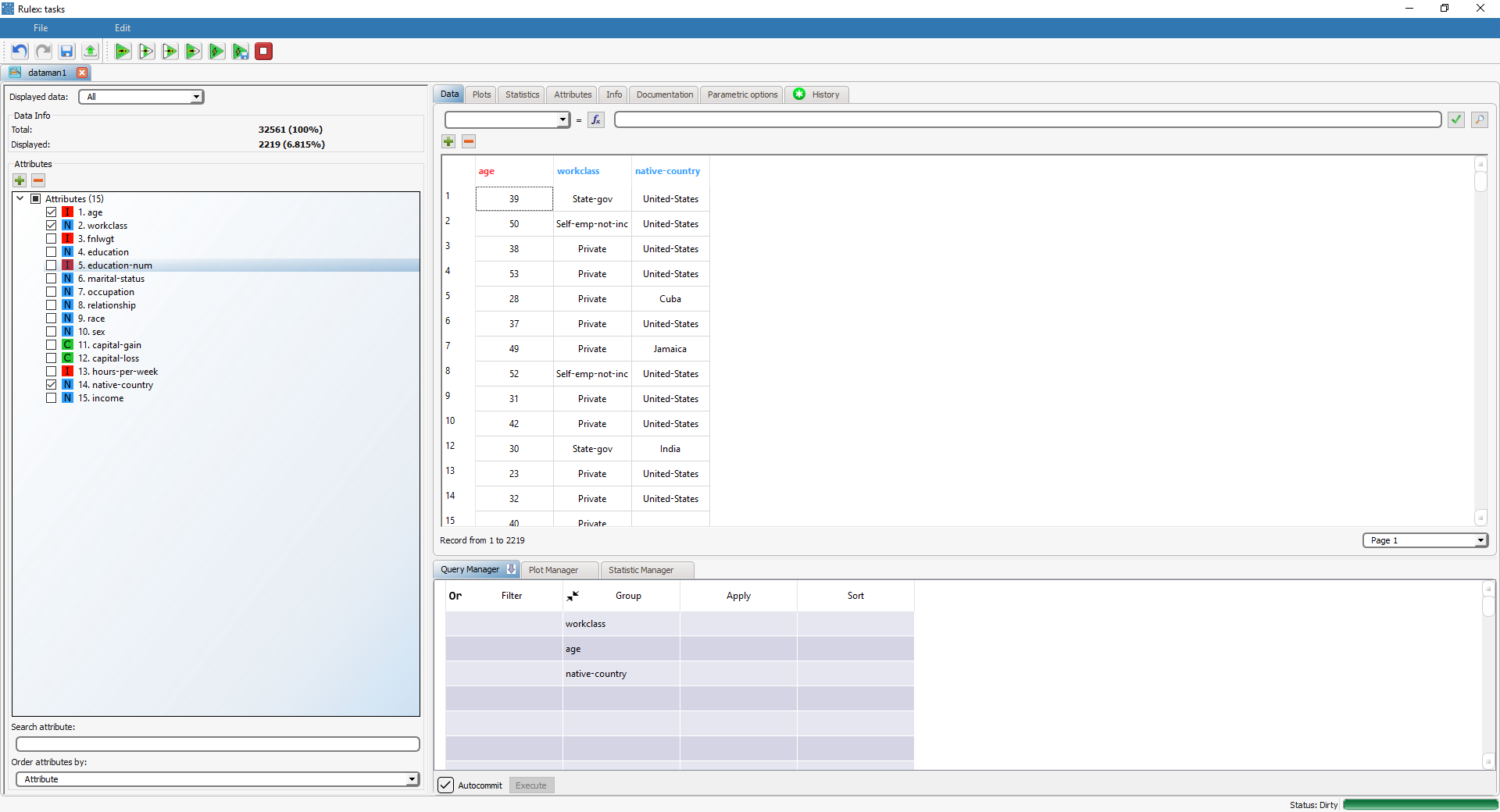
We have grouped the data according to these variables:
age,
workclass, and
native-country.
The number of groups is 2219 since each possible combination of age, workclass and native-country represents a group. For example, the first group consists of 39 year-old people working as State-gov and born in the United-States and so on. Adding more attributes will result in a higher number of groups.