Optimizing Rulesets
The Optimize Rulesets task allows you to modify and consequently improve the generation of predictive rules through a series of constraints.
Prerequisites
the required datasets have been imported into the process
a task has generated a ruleset in the process.
Additional tabs
The following additional tabs are provided:
Documentation tab where you can document your task,
Parametric options tab where you can configure process variables instead of fixed values. Parametric equivalents are expressed in italics in this page.
Procedure
Drag and drop the Optimize Ruleset task onto the stage.
Connect a task, which contains the ruleset you want to modify, to the new task.
Double click the Optimize Ruleset task.
In the Options tab, configure the options as described in the table below.
Save and compute the task.
Optimize Ruleset Options | ||
Parameter Name | Parametric | Description |
|---|---|---|
Maximum number of rules | mrulmaxg | Specify the overall maximum number of rules for the dataset. By default no limitations are imposed. |
Maximum number of conditions | ncondmaxg | Specify the maximum number of conditions that any rule in the final dataset can contain. A lower threshold can improve the readability of rules. By default no limitations are imposed. |
Minimum precision value (%) | minprobg | Specify the minimum percentage of precision that a rule must have. Precision is defined as the ratio between the number of patterns of the correct class covered by the rule and the total number of covered patterns. A lower threshold can improve the quality of rules. By default no limitations are imposed. |
Maximum rule error (%) | errulg | Specify the maximum error (in percentage) that a rule can score. The absolute or relative error is considered according to the whether the Consider relative error instead of absolute option is checked or not. The error is defined as the ratio between the number of patterns belonging to an incorrect class, which are nonetheless covered by the rule and the total number of covered patterns. A lower threshold can improve the accuracy of the rules. By default, no limitations are imposed. |
Minimum covering value (%) | covming | Specify the minimum percentage of covering that each rule in the final dataset must have. Covering is defined as the fraction of patterns belonging to the correct class that are covered by the rule. |
Minimum condition error (%) | errcondg | Sets the minimum error value for each condition in each rule in the final dataset. |
Aggregate data before processing | aggregate | If selected, identical patterns are aggregated and considered as a single pattern during the training phase. |
Consider relative error instead of absolute | relerrmax | Specify whether the relative or absolute error must be considered. The Maximum error allowed for each rule is set by considering proportions of samples belonging to different classes. Imagine a scenario where for given rule pertaining to the specific output value yo:
In this scenario the absolute error of that rule is FP/(TN+FP), whereas the relative error is obtained by dividing the absolute error by TP/(TP+FN) (samples with the output value yo that do verify the conditions of the rule). If checked, the relative error is considered in evaluating the maximum rule error and the minimum condition error. For example, if 10% is the maximum error allowed for a rule, this means that the error cannot be more than the 10% of the covering of the rule. |
Initialize random generator with seed | initrandom | If selected, a seed, which defines the starting point in the sequence, is used during random generation operations. Consequently using the same seed each time will make each execution reproducible. Otherwise, each execution of the same task (with same options) may produce dissimilar results due to different random numbers being generated in some phases of the process. |
Append results | append | If selected, the results of this computation are appended to the dataset, otherwise they replace the results of previous computations. |
Results
The Results of the optimization are displayed in two separate tabs:
the Monitoring tab displays statistics of the selected rules as histograms during the execution of the optimization operation. In particular the distribution of the number of conditions, the covering and the error is showed. Rules relative to different classes are characterized by a a bar of a specific color.
Monitoring plots remain available also at the end of the computation. Notice that, since optimization is performed in an incremental way, it is possible to stop the computation in any moment maintaining the last set of rules without loosing the coherence of the results. See the example below for further details.the Results tab displays a summary of the performed computation, such as the execution time, number of rules before and after optimization etc.
Example
The following examples are based on the Adult dataset.
Scenario data can be found in the Datasets folder in your Rulex installation.
The scenario aims optimize the rules generated by a classification Logic Learning Machine block.
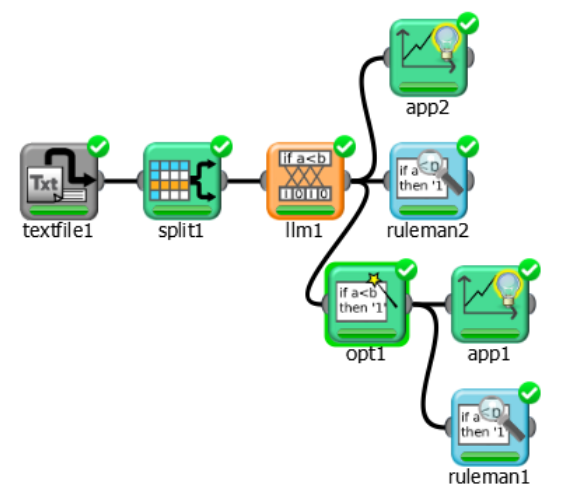
The following steps were performed:
First import the adult dataset via an Import from Text File task.
Then split the dataset into a training and test set.
Then generate a set of rules through the Logic Learning Machine task.
Check the generated ruleset with the Rule Manager task.
Add an Apply Model task to forecast the output value on the basis of the set of rules.
Optimize the set of rules via an Optimize Ruleset task.
Check the newly generated ruleset with the Rule Manager task.
Add another Apply Model task to forecast the output value on the basis of the new set of rules.
View the results and forecast accuracy through the Take a look feature.
Procedure | Screenshot |
|---|---|
First of all import the adult dataset using an Import from Text File task. Save and compute the task. | 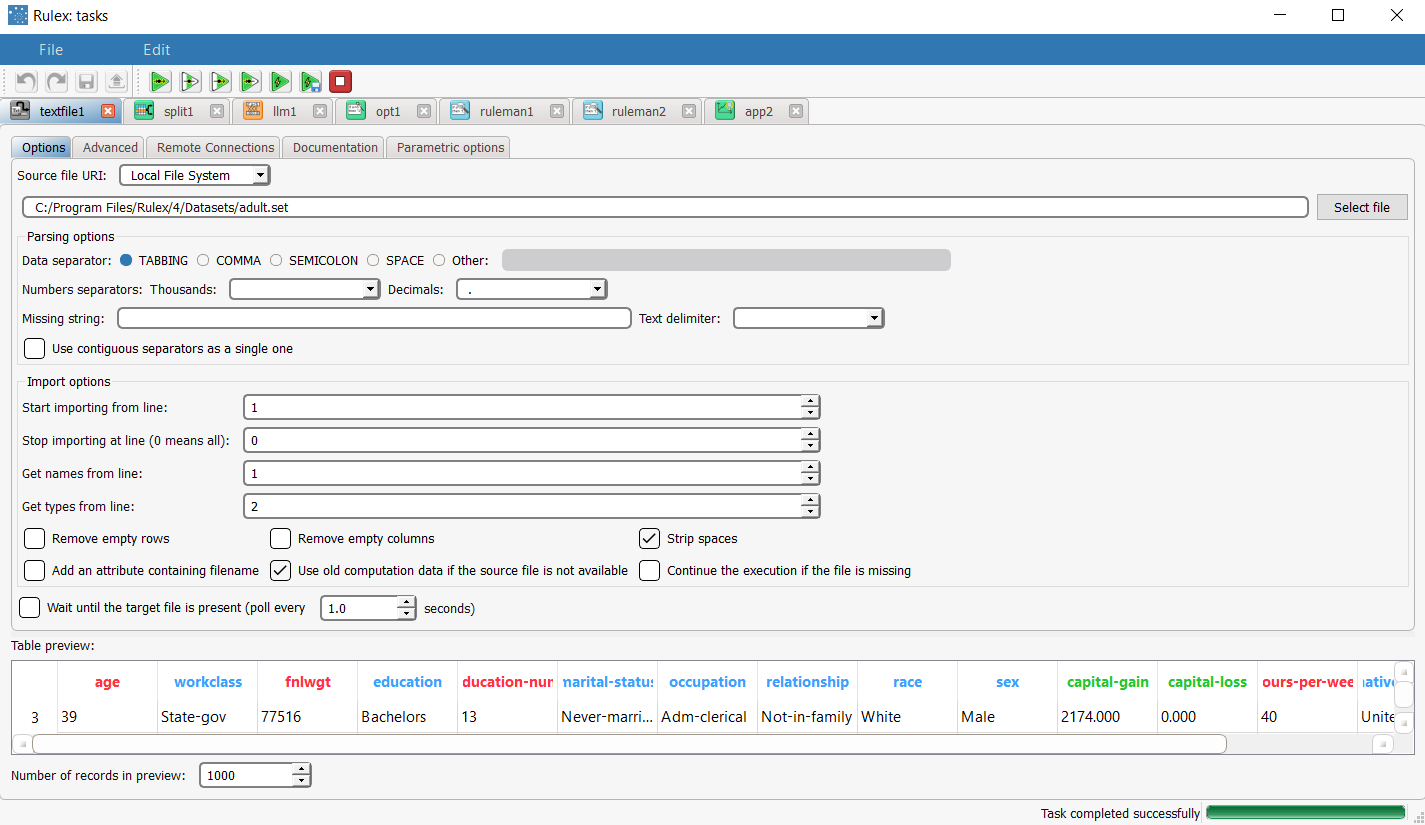 |
Split the dataset into 70% for the training set, and 30% for the test set in the Split Data task. Save and compute the task. | 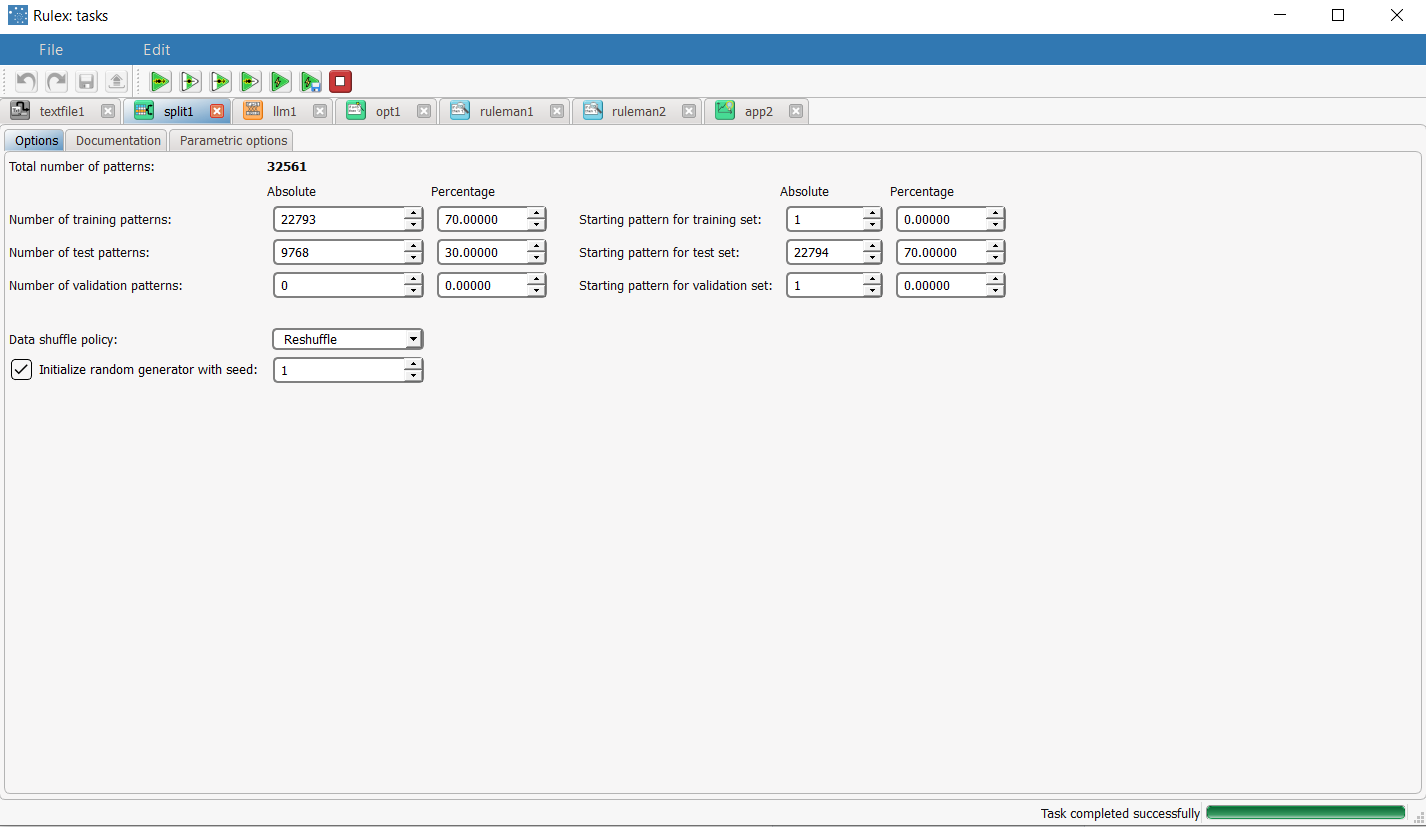 |
Add a Classification LLM task to the process, and drag and drop the Income attribute onto the Output Attributes list, to define it as the outcome for the classification analysis. Save and compute the task. | 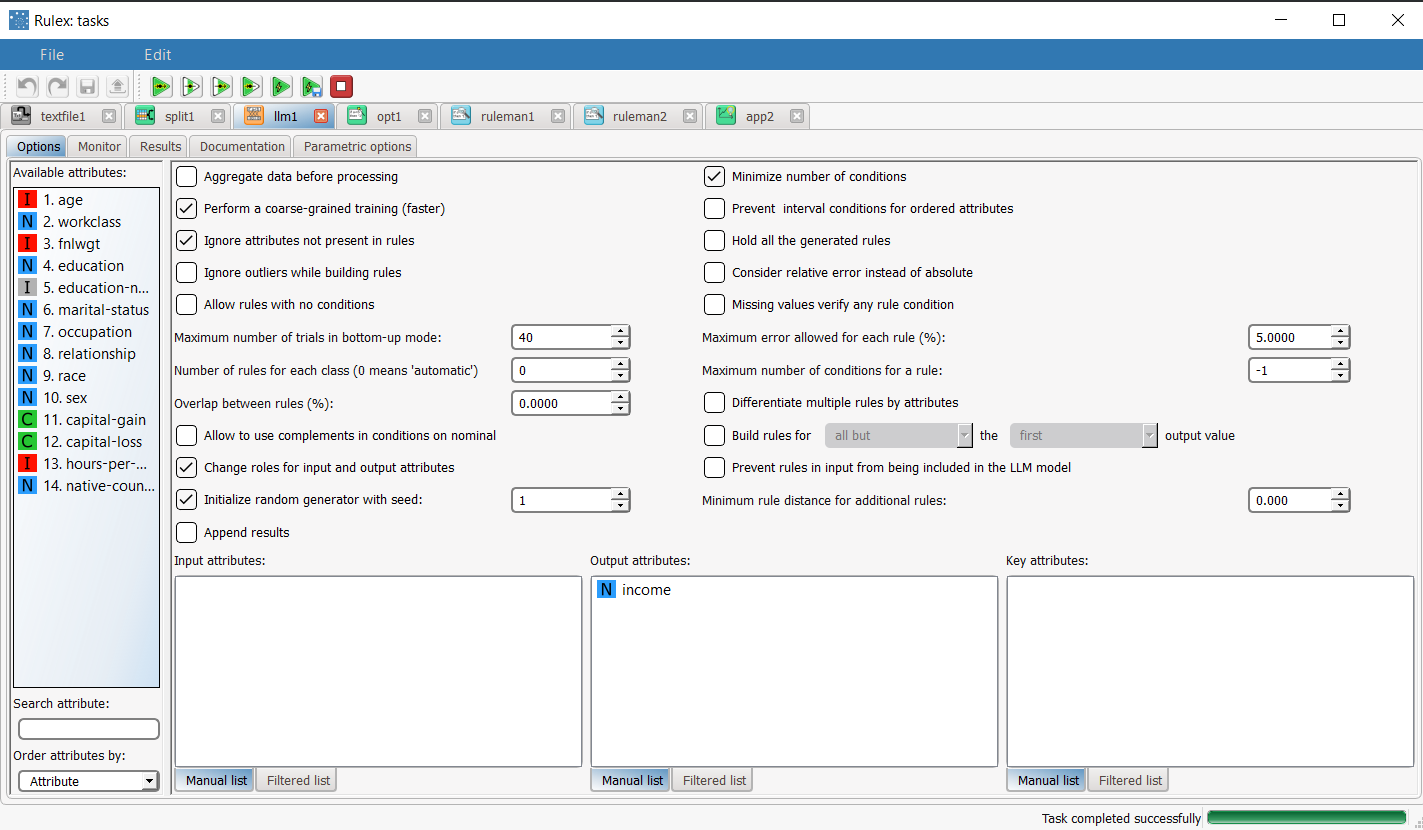 |
Add a Rule Manager task to the process to check which rules have been generated by the LLM task. 62 rules have been generated, with a maximum of 11 conditions. | 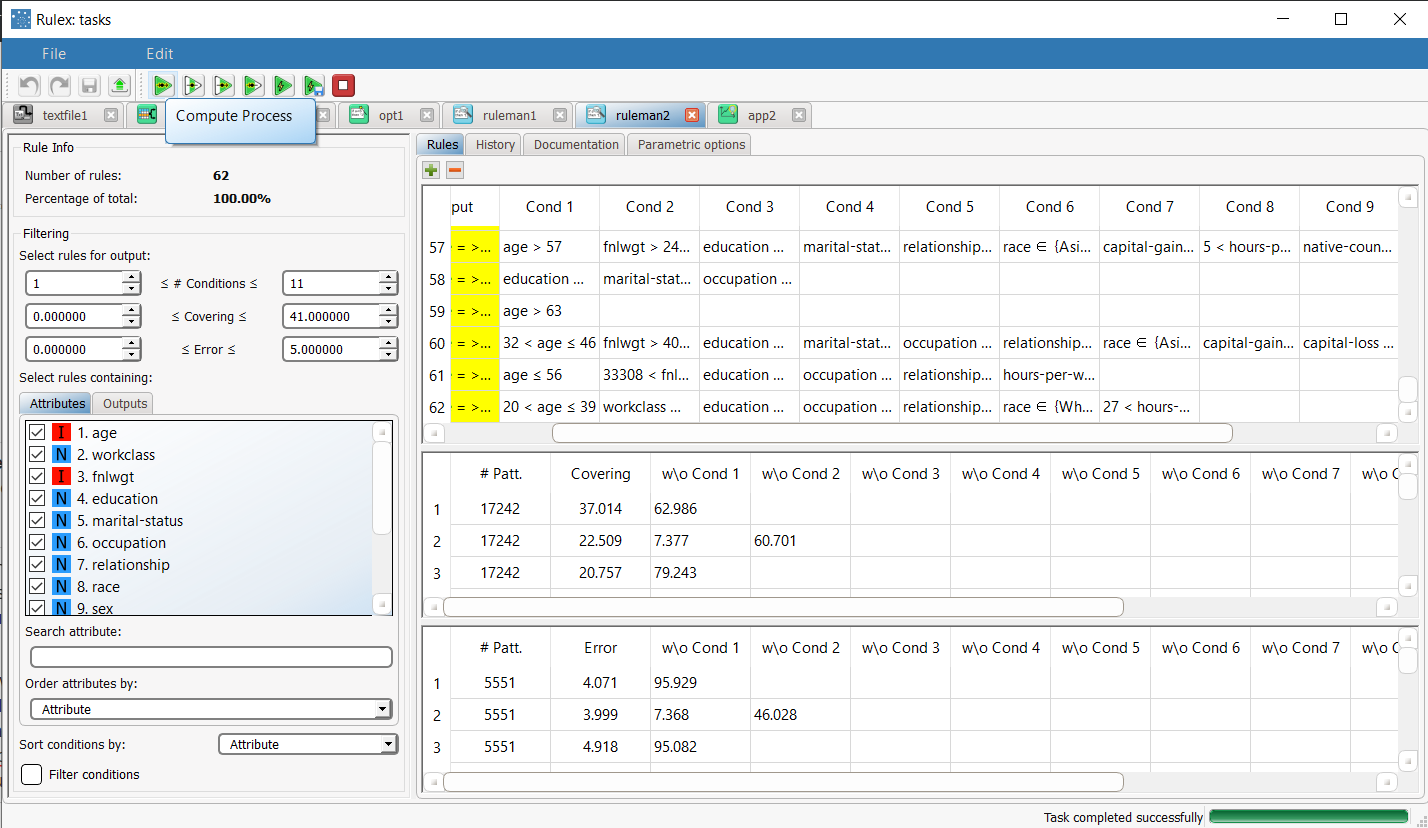 |
To check how these rules perform on new data, add an Apply Model task to the LLM task, and compute the task with default options. Then right-click the task, and select Take a look. The overall accuracy is about 80%, with around 80% for both the Test and Training datasets. | 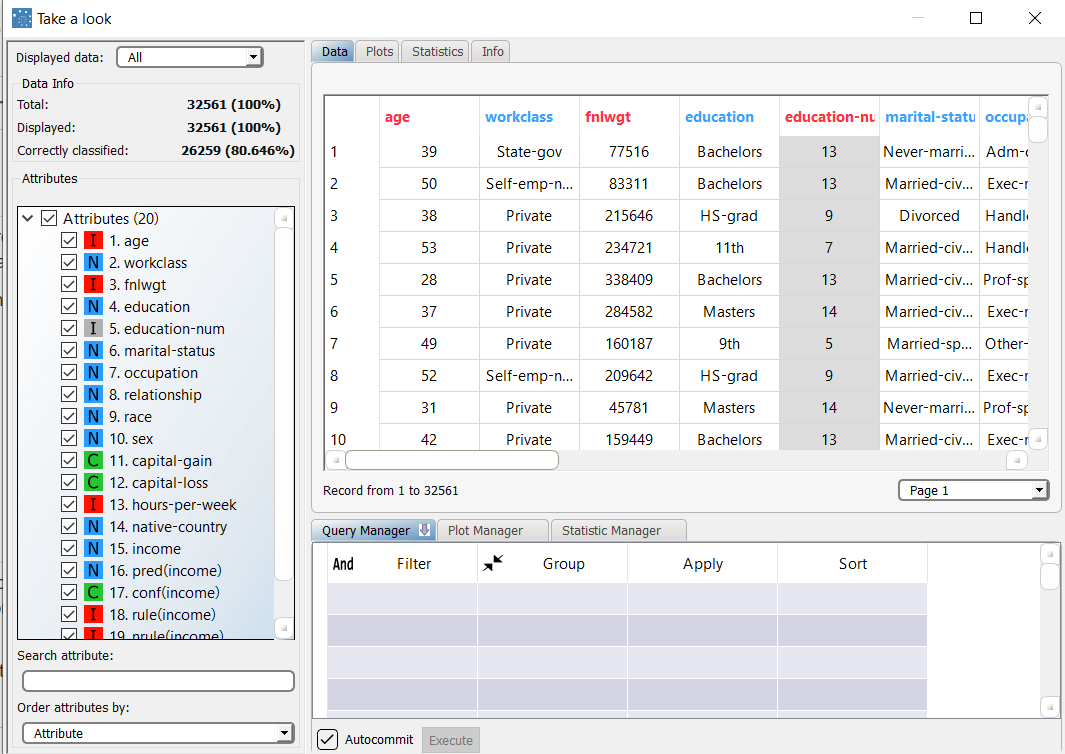 |
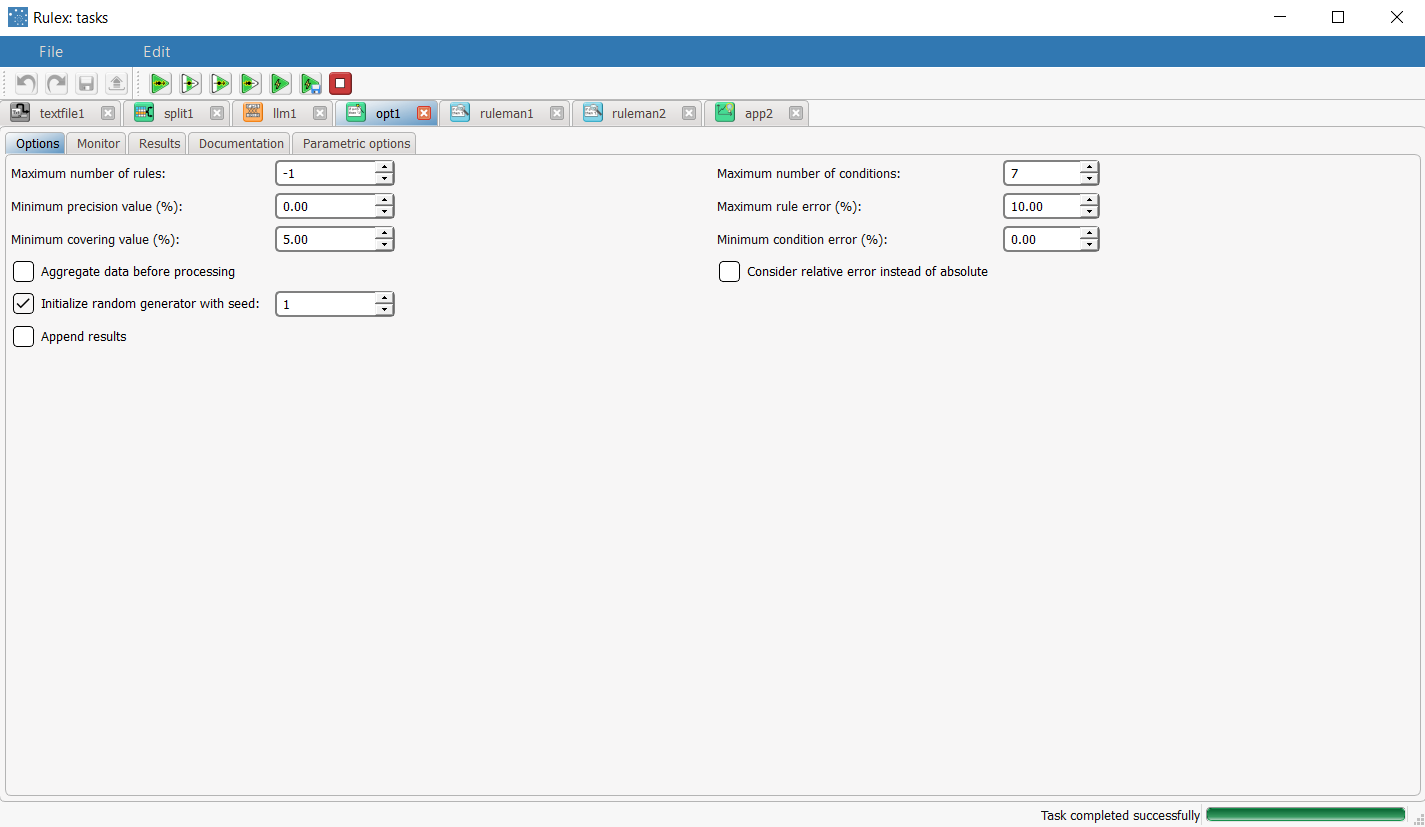
To improve on these results, add an Optimize Ruleset task to the LLM task, and configure as follows:
|  |
Add a Rule Manager task to the Optimize Ruleset task to check the new rules have been generated by the LLM task after optimization. The optimized set of rules is made up of only 11 rules (instead of the original 62), which have a maximum covering of 58.4%. Now we want to verify whether the new set of rules performs well on the examples of the dataset. | 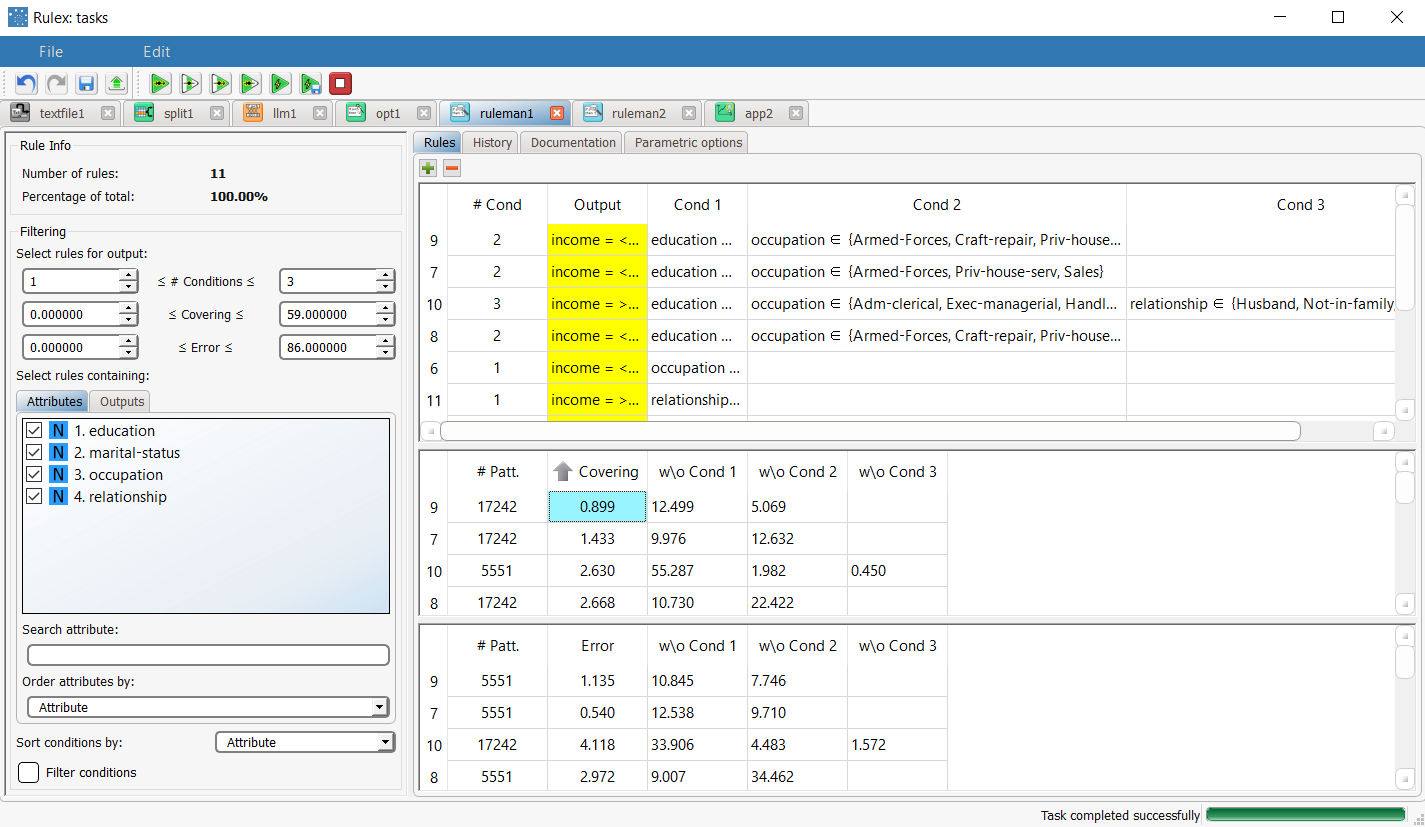 |
Add an Apply Model task to the Optimize Ruleset task, and compute the task with default options. Then right-click the task, and select Take a look. The overall accuracy is now about 77.6%, with around 77% for the Training dataset and 78% for the Test dataset. Although accuracy has slightly reduced, the optimization task was able to extract a reduced set of rules, which are much simpler, with far fewer conditions, which are equally capable of correctly forecasting the class of previously unseen patterns. | 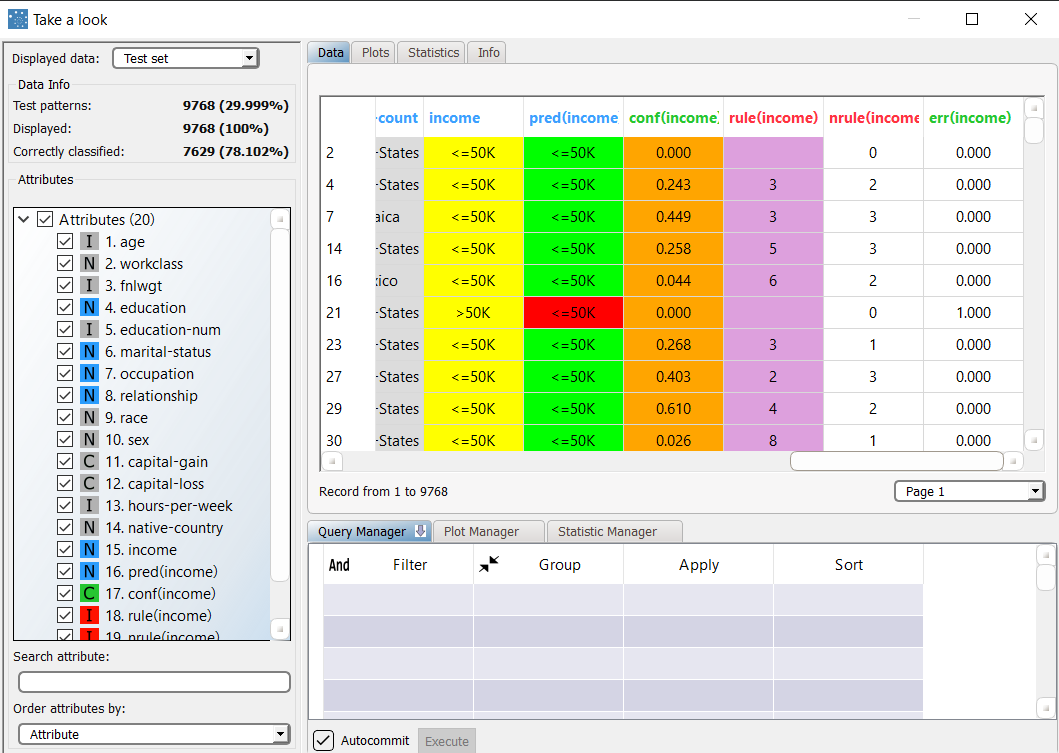 |