Using Frequent Itemsets Mining to Solve Association Problems
Frequent itemset mining extracts recurrent item associations from a dataset. Rulex uses the Equivalence Class Transformation (Eclat) algorithm to perform this task.
A typical scenario in which this task could be applied is in defining which items are frequently bought together in a supermarket.
The output would be a table of itemsets which are bought in the same transaction more than a specified number of times. However, the task can be used in many other scenarios, whenever it is possible to identify attributes which define groups (Order key attributes) and attributes that populate these groups with information (Item key attributes).
Rulex can handle both:
generalized frequent itemset mining, where the items refer to different attributes and consequently carry different information
hierarchical frequent itemset mining, where the attributes carry the same information with different levels of detail.
Prerequisites
the required datasets have been imported into the process
the data used for the model has been well prepared
a single unified dataset has been created by merging all the datasets imported into the process.
Additional tabs
The following additional tabs are provided:
Documentation tab where you can document your task,
Parametric options tab where you can configure process variables instead of fixed values. Parametric equivalents are expressed in italics in this page (PO).
Frequent Itemsets & Results tabs, where you can see the output of the task computation. See Results table below.
Procedure
Drag and drop the Frequent Itemset Mining task onto the stage.
Connect a Data Manager task, which contains the attributes from which you want to extract the associations, to the new task.
Double click the Frequent Itemset Mining task. The left-hand pane displays a list of all the available attributes in the dataset, which can be ordered and searched as required.
Configure the Basic options described, as described below.
Click on the Advanced tab to configure the frequent itemsets advanced options, as described below.
Click on the Output tab to configure the output options, as described below.
Save and compute the task.
Frequent Itemsets Mining Basic options | ||
Name | PO | Description |
|---|---|---|
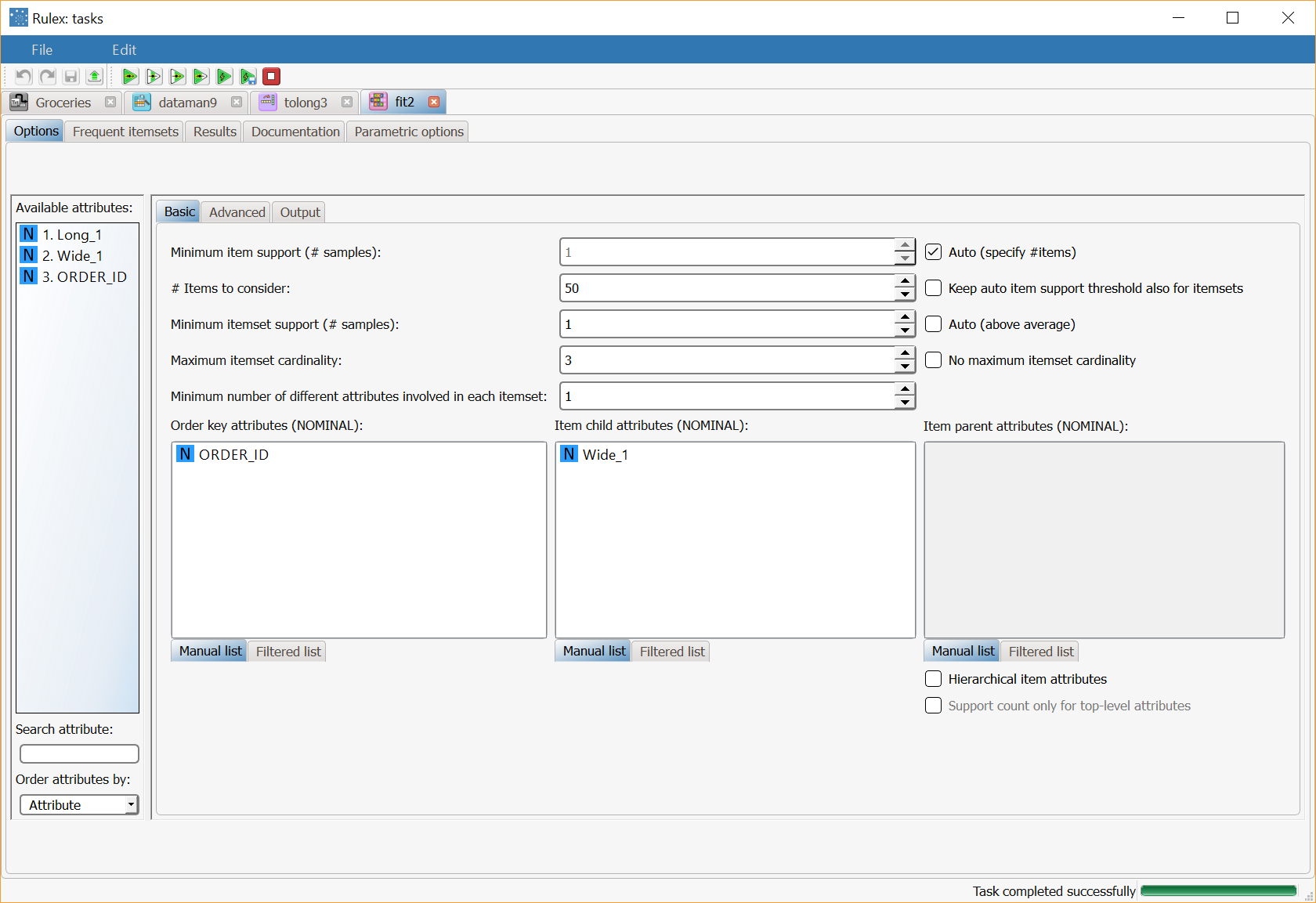
Order key attributes | mbaorderkeynames | Drag and drop the nominal attributes which define orders from the Attributes list onto this list. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. |
Item child attributes | mbaitemchildnames | Drag and drop the nominal attributes which characterize items from the Attributes list onto this list. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. |
Item parent attributes | mbaitemparentnames | Drag and drop the nominal attributes which correspond to the hierarchically superior level of the attribute inserted in the Item child attributes list. For example, if the analysis involves EAN codes and categories, the EAN code is dragged and dropped onto the Item child attributes list, while the category is inserted in the same position of the Item parent attributes list. If the parent item attribute is not defined for any child instances (i.e. an EAN is not categorized), the child attribute value is repeated in the parent attribute column. This list is enabled only if the Hierarchical item attributes option is selected. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. |
Hierarchical item attributes | mbastricthierattr | If checked, this option denotes the existence of hierarchical attributes which characterize items, consequently enabling the Item parent attributes list. |
Support count only for top-level attributes | mbahierincl | If checked, this option modifies support computation so that only top-level attributes in a hierarchy are taken into account. If this option is not checked, for every order, all included elements of the hierarchy increment their support by 1. |
Minimum item support (# samples) | supth | All items which appear in orders fewer times than this threshold are discarded. This value is relevant only if the Auto (specify #items) option is unchecked. |
Auto (specify # items) | mbaspecnitem | If selected, the minimum support for items is automatically computed, and the number of items to be taken into account can be specified in the Items to consider spin box. |
Items to consider | mbanitemsup | This option is enabled only if the Auto (specify # items) option is selected. The number of items to take into account (most frequent first). |
Keep auto item support threshold also for itemsets | mbaextspecnitem | This option is enabled only if the Auto (specify # items) option is not selected. If selected, all itemsets which occur fewer times than this threshold are discarded. |
Minimum itemset support (# samples) | assupth | This option is enabled only if the Auto (specify # items) option is not selected. All itemsets which occur fewer times than this threshold are discarded. |
Auto (above average) | abavassupth | If selected, the minimum itemset support value is set to the average support of itemsets with the same dimension. |
Maximum itemset cardinality | fitmaxdim | The maximum cardinality of generated itemsets. |
No maximum itemset cardinality | fitnomaxdim | If selected, all itemsets with higher support than the specified threshold are generated, regardless of their cardinality. |
Minimum number of different attributes involved in each itemset | mbadiffattr | Determines the minimum number of different attributes that have to be part of an itemset in order not to discard it. |
Frequent Itemsets Mining Advanced options | ||
Attribute to filter to select rows including relevant data | Drag and drop attributes to this edit box (from the Available attributes, the Order key attributes, the Item key attributes or the Auxiliary attributes list) to specify a filtering criterion. Items satisfying this criterion are not discarded, regardless their support. | |
Attribute to filter to discard rows including irrelevant data | Drag and drop attributes to this edit box (from the Available attributes, the Order key attributes, the Item key attributes or the Auxiliary attributes list) to specify a filtering criterion. Items which appear in rows satisfying this criterion are discarded, regardless their support. If both the selecting and the discarding filters are specified, the discarding filter prevails. | |
Maximum factor per auxiliary attribute adjusting support | mbaauxw | Specify the value up to which the support of items and associations may be multiplied or divided, according to the average value of its auxiliary attribute(s). |
Auxiliary attributes | mbaauxnames, | Auxiliary attributes are used to take additional criteria into account (together with support) when filtering itemsets. For instance, it is possible to take into account item and itemsets whose support is low if their margin is greater than the average and, symmetrically, to discard itemsets even if they have high support, if their margin is lower than average. Drag and drop attributes (from the Available attributes list):
Drag and drop those attributes for which you want to calculate their overall quantity in the Item quantities target list. |
Frequent Itemsets Mining Output options | ||
Flag maximal frequent itemsets | fitonlymax | If selected a column is added to the table which specifies whether a frequent itemset is maximal or nor, i.e. whether or not it is not included within another frequent itemset or not. |
Rare itemsets mining | mbaminerareit | If selected, the output will display rare itemsets instead of frequent itemsets. Rare itemsets are groupings of items that are rarely found together, although they may be frequent individually. |
Maximum itemset support | maxassupth | This threshold value indicates the maximum number of times the items in an itemset can be found together in order to be considered rare. |
Maximum relative support for itemsets | maxrelsupth | The support value compares the number of times the item appears with and without the other item in the rare itemset. |
Results
The results of the task are displayed in two separate tabs:
The Frequent itemsets tab displays the generated item sets, where:
Frequent ItemsetID is the sequential ID number for frequent itemsets.
Cardinality is the cardinality of the frequent itemset.
Support is the percentage of orders in which the frequent itemset appears in the dataset.
Support# is the number of times the frequent itemset appears in the dataset.
All-confidence is the ratio between the support of the itemset and the support of the least frequent item included in the itemset.
Item ID is the ID of the items composing the frequent itemset reported in these columns.
The Results tab displays details on the execution of the analysis, where:
Task Identifier is the ID code for the task, internally used by the Rulex engine.
Task Name is simply the name of the task.
Elapsed time (sec) is the time required for latest computation (in seconds).
Number of generated frequent itemsets is the number of itemsets which were found to be frequent, according to the support threshold.
Number of different items in input is the number of distinct items which were fed to the task during latest computation.
Number of different orders in input is the number of distinct orders which were fed to the task during latest computation.
Example
In the example process, frequent itemsets are extracted from an imported dataset. The Groceries dataset, used in the scenario, contains 9835 supermarket transactions in separate rows.
Scenario data can be found in the Datasets folder in your Rulex installation.
The following steps were performed:
First we import the Groceries dataset.
The data is prepared in the dataman1 Data Manager task.
The dataset is restructured in the tolong1 Reshape To Long task.
Frequent sequences are extracted with the fit1 Frequent Itemsets Mining task.
Procedure | Screenshot |
|---|---|
First we import the Groceries dataset with an Import from Text File task, setting the data separator to comma, and the Get names from line option to 0. | 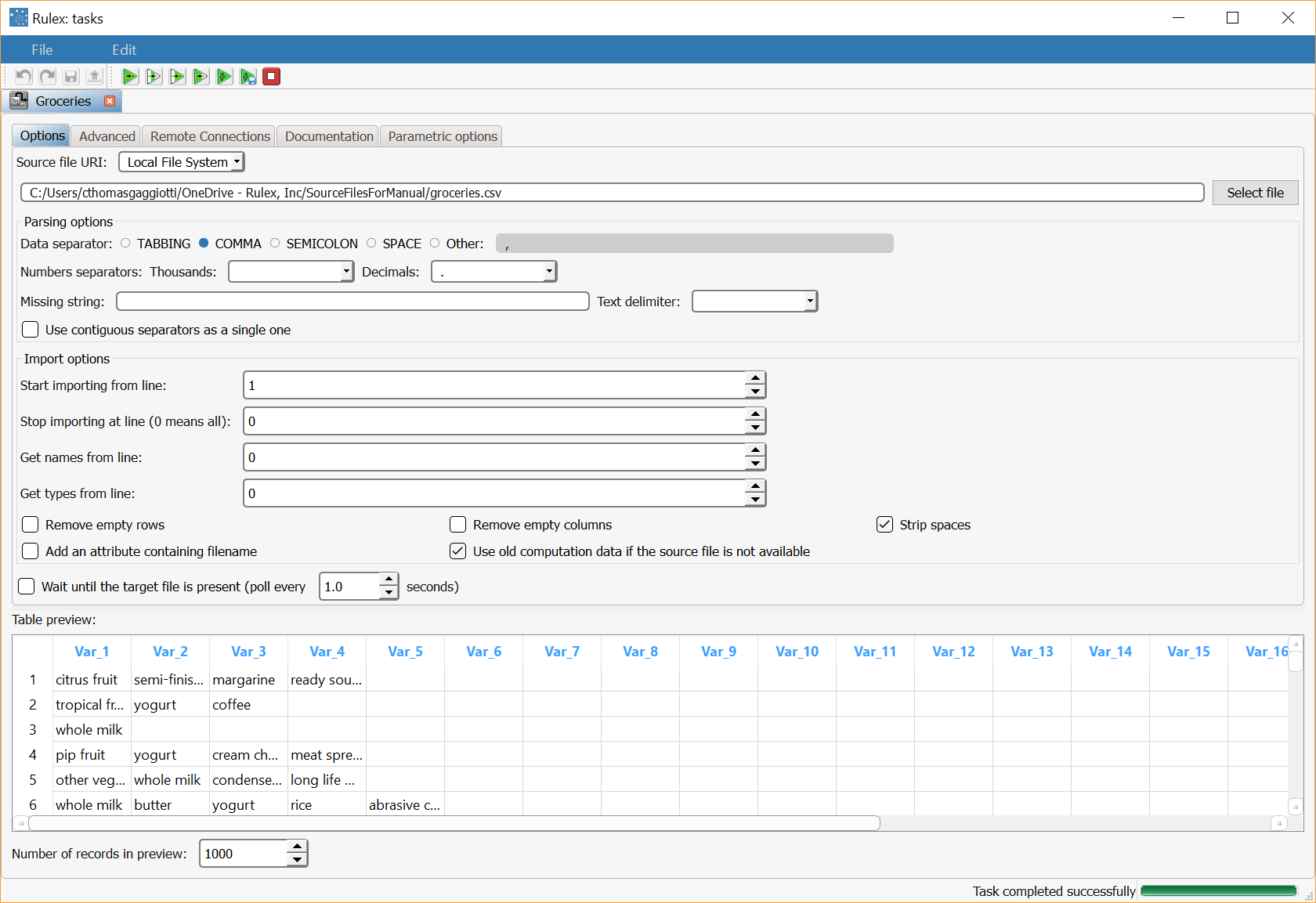 |
Double click the Data Manager task, and add a new attribute column to the dataset, called ORDER_ID, by clicking the plus + icon above the Attributes list. In order to use this attribute to identify each transaction, create a formula in the formula bar, with the ORDER_ID attribute on the left-hand side and the enum() function on the right-hand side. Set the attribute type to Nominal in the Attributes tab, then save and compute the task. | 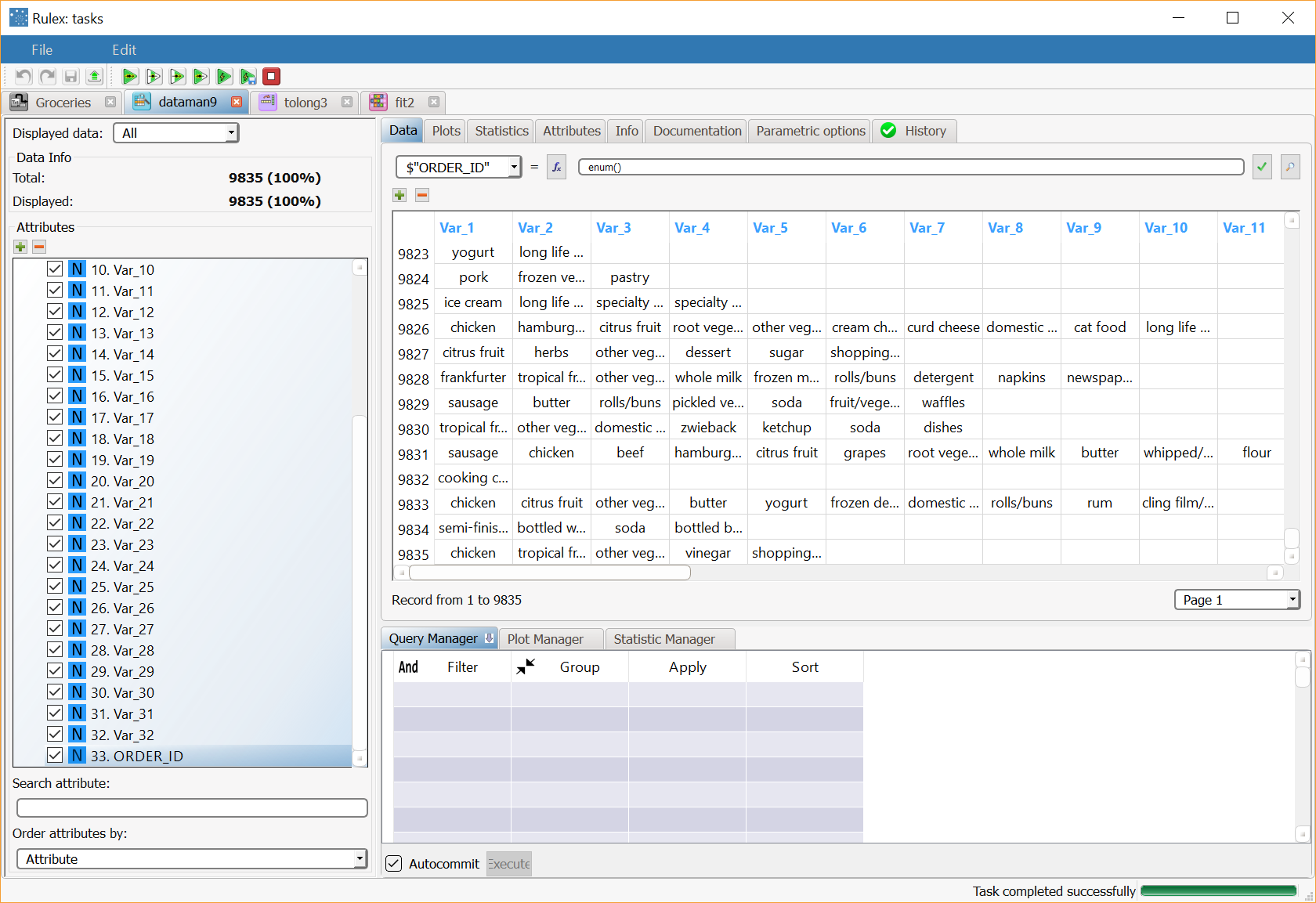 |
The current format of the dataset is not suitable for the Frequent Itemsets Mining task as each row represents a full transaction and not a single purchase. The dataset must be restructured so that the information concerning a purchase of n items is distributed over n rows, each one including a Order ID/Item ID pairing. The dataset can be restructured by adding a Reshape To Long task to the process. |  |
Double-click the Reshape To Long task and drag all the attributes from the left, apart from the ORDER_ID attribute, onto the Attributes to be transformed in long format target list. Save and execute the task. | 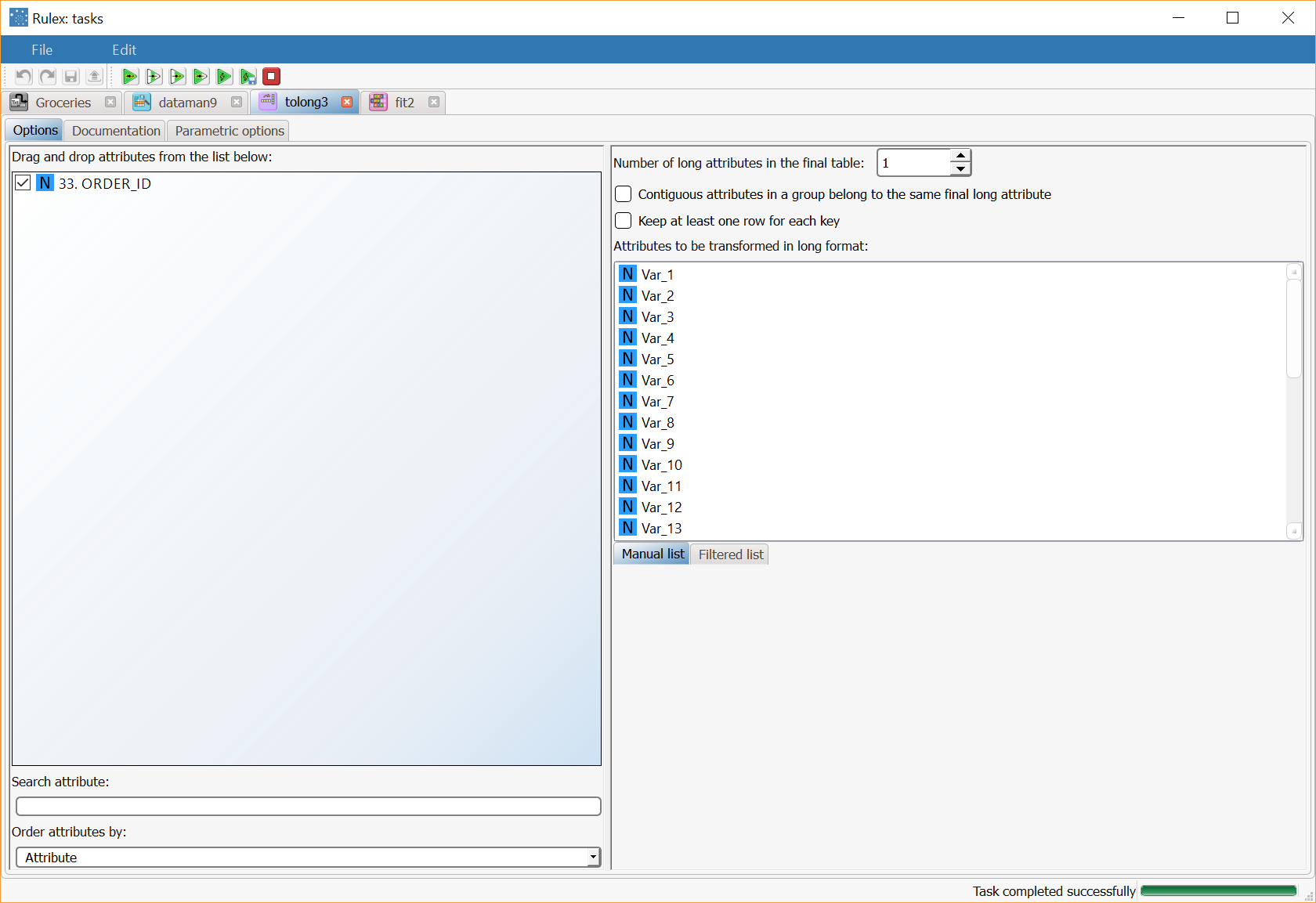 |
Right-click the Reshape To Long task and select Take a look to check the new structure. The dataset is now structured with a row for every single purchase. | 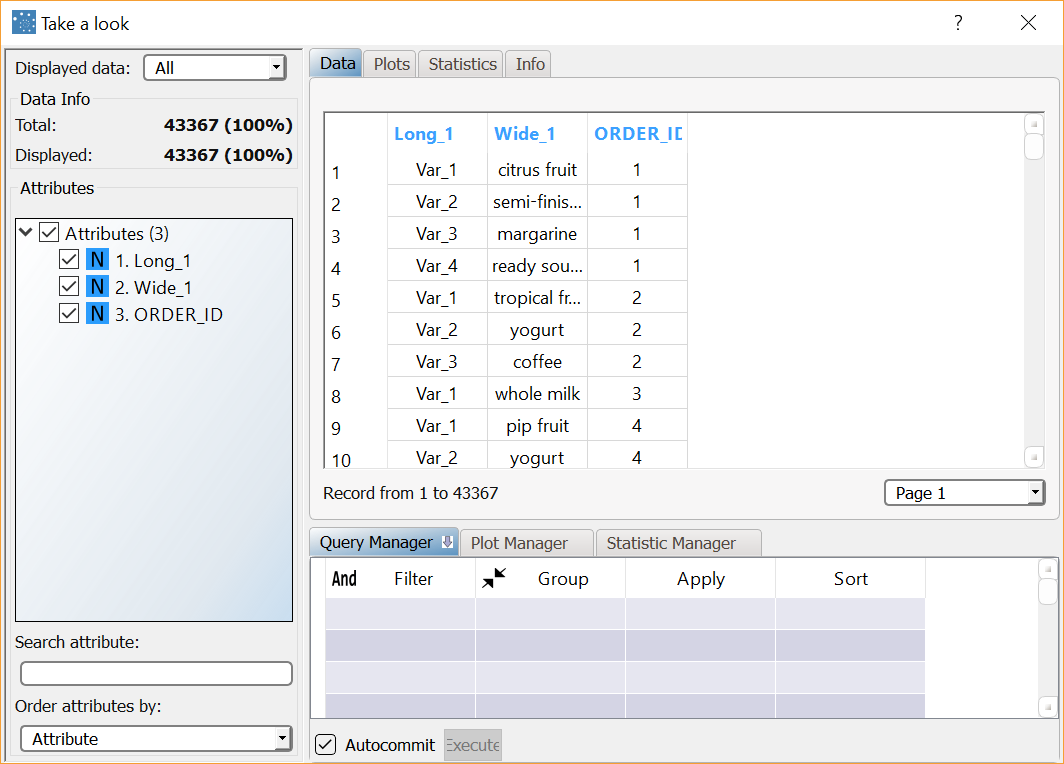 |
Now add a Frequent Itemsets Mining task, and configure the task as follows:
|  |
The resulting itemsets are displayed in the Frequent Itemsets tab. | 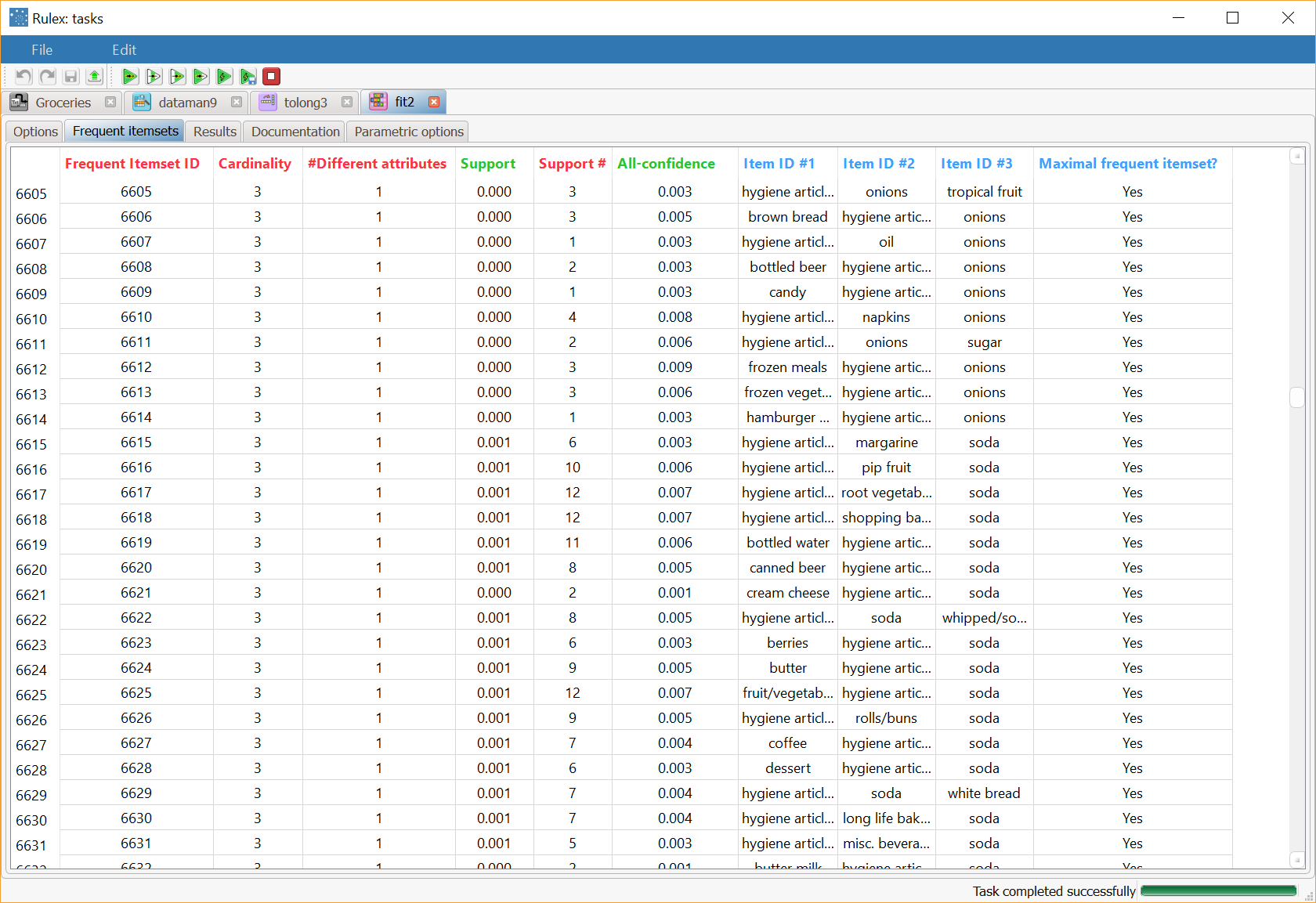 |