Using SVM to Solve Classification Problems
The SVM task trains a Support Vector Machine for classification. The SVM model uses a kernel function (a generalization of scalar product) to find the optimal separating surfaces in data.
The output of the task is a model, containing a weight matrix wji ,that can be employed by the Apply Model task to perform the SVM forecast on a set of examples.
Prerequisites
the required datasets have been imported into the process
the data used for the model has been well prepared, and contains a categorical output and a number of inputs.
a single unified dataset has been created by merging all the datasets imported into the process.
Additional tabs
Along with the Options tab, where the task can be configured, the following additional tabs are provided:
Documentation tab where you can document your task,
Parametric options tab where you can configure process variables instead of fixed values. Parametric equivalents are expressed in italics in this page (PO).
Monitor and results tabs, where you can see the output of the task computation. See Results table below.
Procedure
Drag and drop the SVM task onto the stage.
Connect a task, which contains the attributes from which you want to create the model, to the new task.
Double click the SVM task.
Configure the options described in the table below.
Save and compute the task.
SVM options | ||
Parameter Name | PO | Description |
|---|---|---|
SVM formulation | svmtype | Select the formulation for the SVM problem. Possible choices are:
|
Gamma in kernel function | svmgamma | Specify the value of the parameter γ in the kernel function. Note this parameter is only required for Polynominal, Radial basis function and Sigmoid kernel functions. |
Kernel function | svmkernel | Indicate the kernel function to be used. Possible choices are:
|
Coef0 in kernel function | svmcoeff0 | Specify the value of the parameter c0 in the kernel function. Note this parameter is only required for Polynominal and Sigmoid kernel functions. |
Degree in kernel function | svmdegree | Specify the value of the parameter d in the kernel function. Note this parameter is only required for Polynominal kernel functions. |
Parameter C of C-SVC | svmcost | Specify the value of the parameter C in the SVM formulation. |
Normalization for input variables | normtype | The type of normalization to use when treating ordered (discrete or continuous) variables. Every attribute can have its own value for this option, which can be set in the Data Manager task. These choices are preserved if Attribute is selected in the Normalization of input variables option; otherwise any selections made here overwrite previous selections made. |
Parameter nu of nu-SVC | svmnu | Specify the value of the parameter ν in the nu-SVM formulation. |
Use shrinking heuristics | svmshrinking | If selected, heuristic methods will be used to speed up computation. |
Tolerance threshold | svmtol | Specify the tolerance of the terminating criterion. |
Aggregate data before processing | aggregate | If selected, identical patterns are aggregated and considered as a single pattern during the training phase. |
Cache memory size | svmcachesize | Specify the amount of cache that can be used during training. |
Initialize random generator with seed | initrandom, iseed | If selected, a seed, which defines the starting point in the sequence, is used during random generation operations. Consequently using the same seed each time will make each execution reproducible. Otherwise, each execution of the same task (with same options) may produce dissimilar results due to different random numbers being generated in some phases of the process. |
Append results | append | If selected, the results of this computation are appended to the dataset, otherwise they replace the results of previous computations. |
Input attributes | inpnames | Drag and drop the input attributes you want to use to build the network. |
Output attributes | outnames | Drag and drop the attributes you want to use to build the model. |
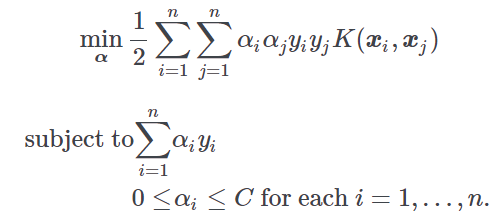
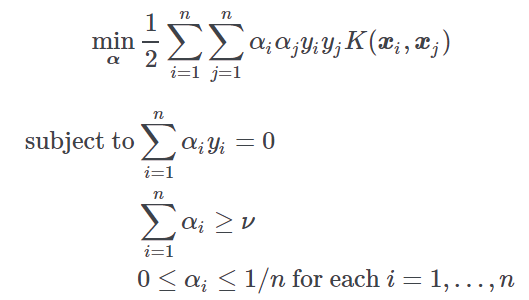
Results
The results of the SVM task can be viewed in two separate tabs:
The Monitor tab, where it is possible to view the temporal evolution of some quantities related to the SVM optimization during its execution. In particular, the behavior of tolerance, and its minimum is reported as a function of the number of iterations. These plots can be viewed during and after computation operations.
The Results tab, where statistics on the SVM computation are displayed, such as the execution time, number of attributes etc..
Example
The following examples are based on the Adult dataset.
Scenario data can be found in the Datasets folder in your Rulex installation.
The scenario aims to solve a simple classification problem based on ranges on income.
The following steps were performed:
First we import the adult dataset with an Import from Text File task.
Split the dataset into a test and training set with a Split Data task.
Generate the model from the dataset with the SVM task.
Apply the model to the dataset with an Apply Model task, to forecast the output associated with each pattern of the dataset.
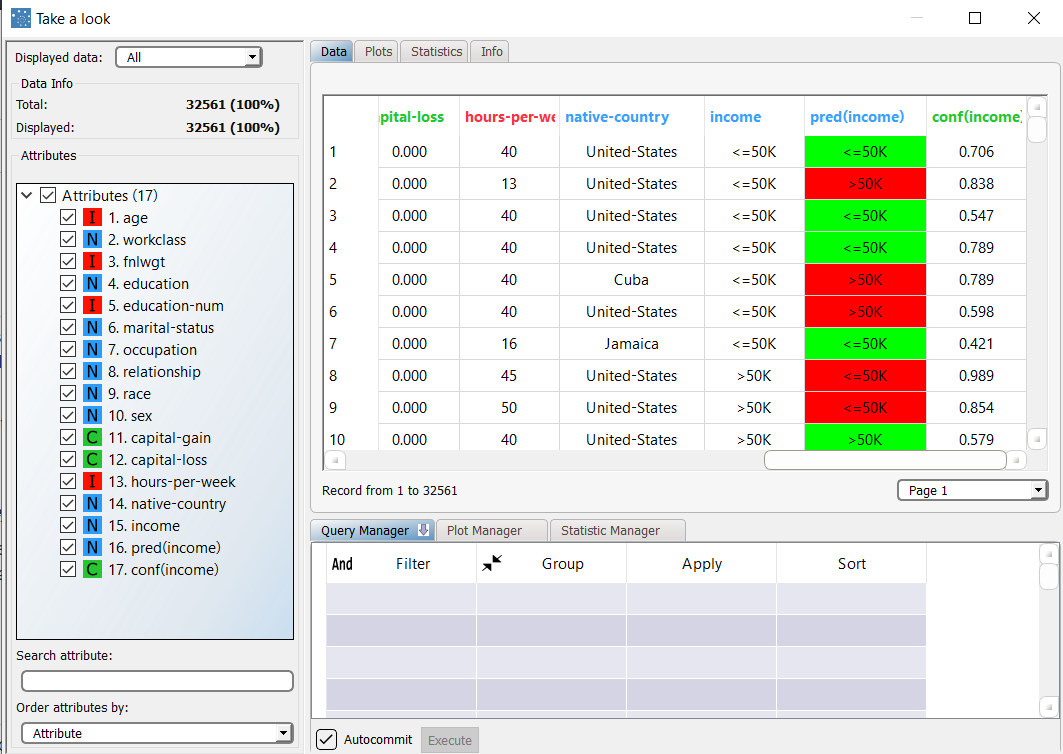
View the results of the forecast via the Take a look function.
Procedure | Screenshot |
|---|---|
Import the adult dataset with the Import from Text File task, and take the data types from line 2. |  |
Split the dataset into test and training sets (30% test and 70% training) with the Split Data task. | 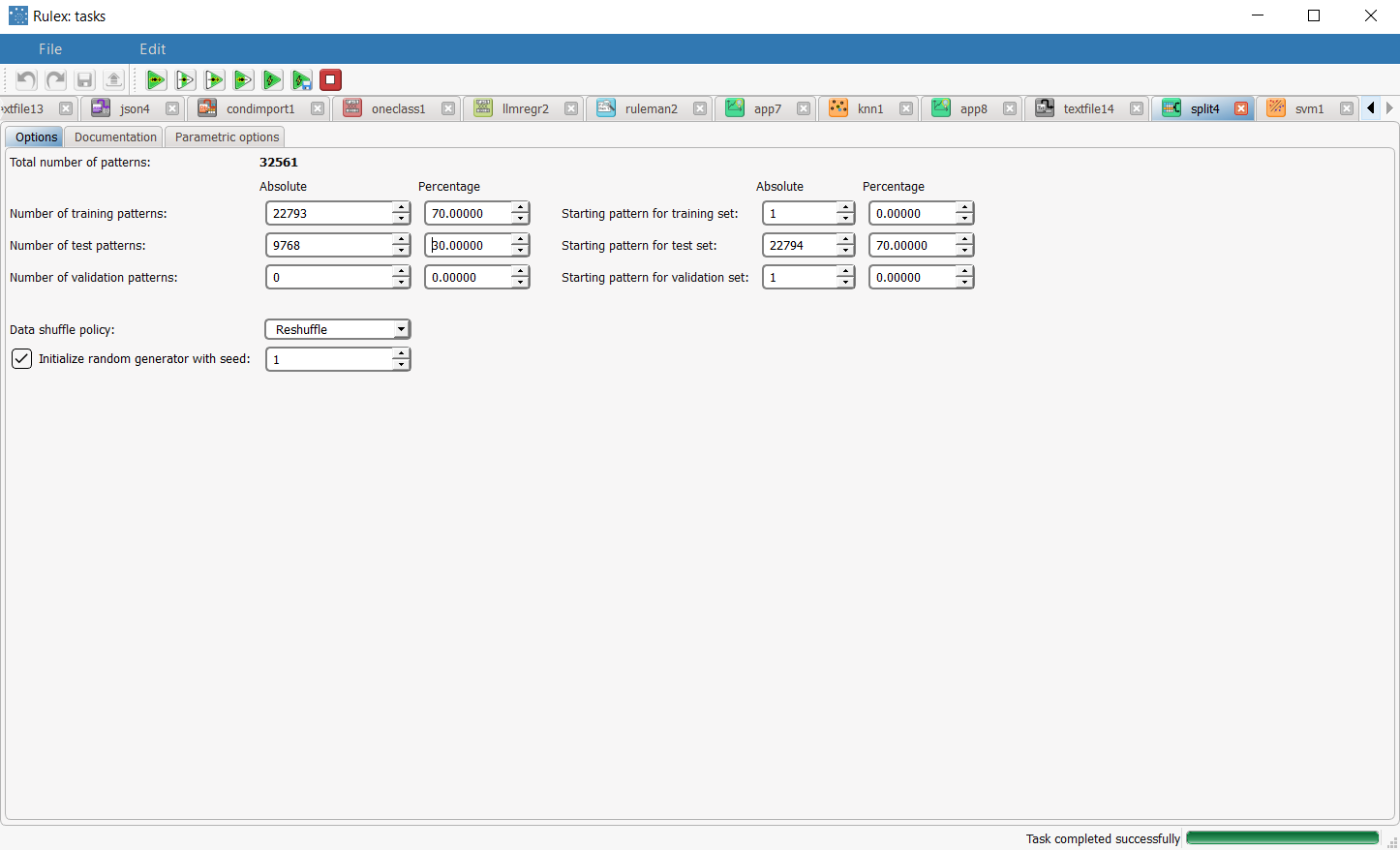 |
Add an SVM task to the process and double click the task. Drag and drop the Income attribute onto the Output Attributes edit box, then the following attributes as input attributes:
Configure these options as follows:
Leave the remaining default settings, then save and compute the task. | 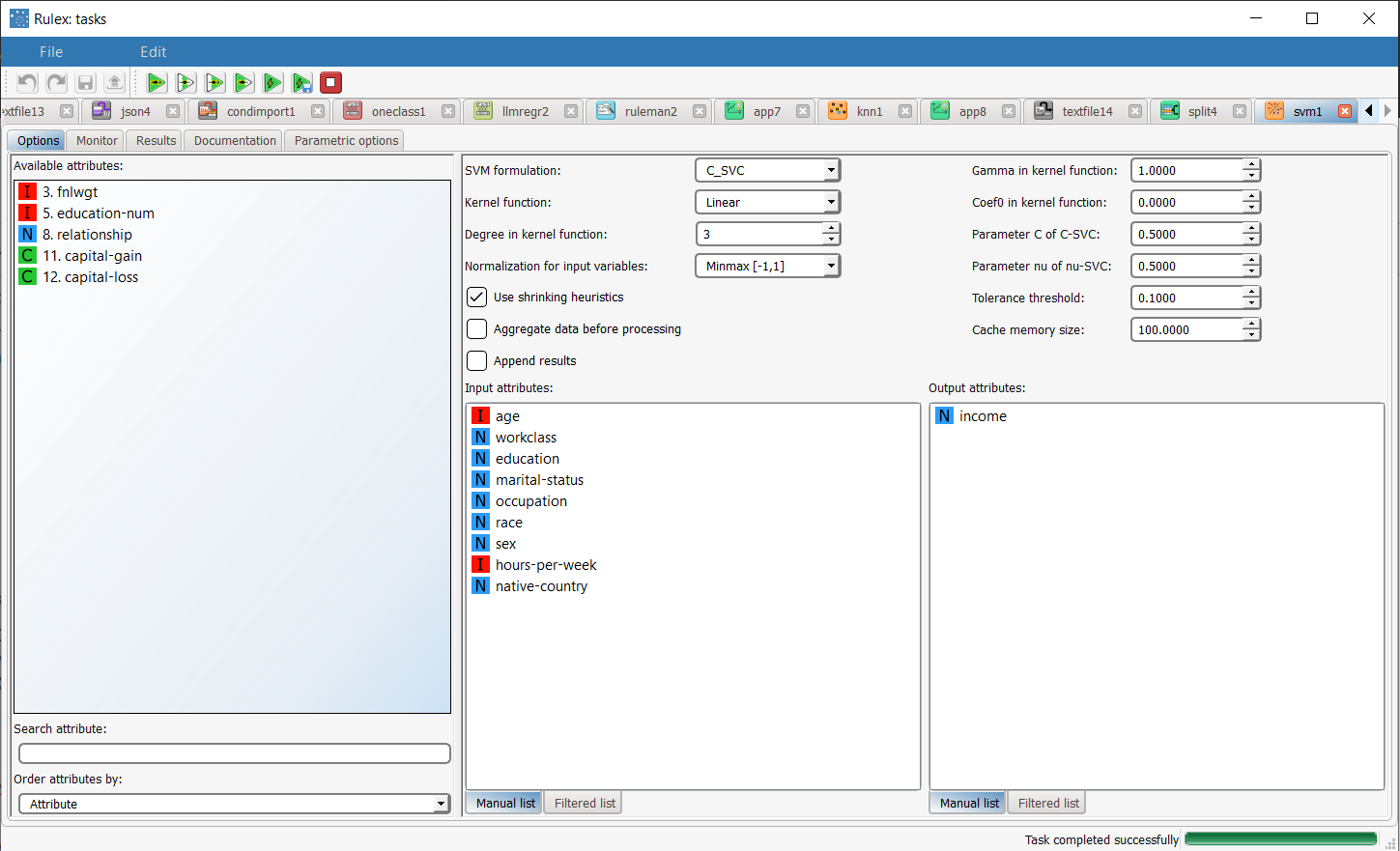 |
The execution of the SVM task can be viewed in the Monitor tab. In these plots the behavior of the tolerance (and its minimum) as a function of the iteration is showed. | 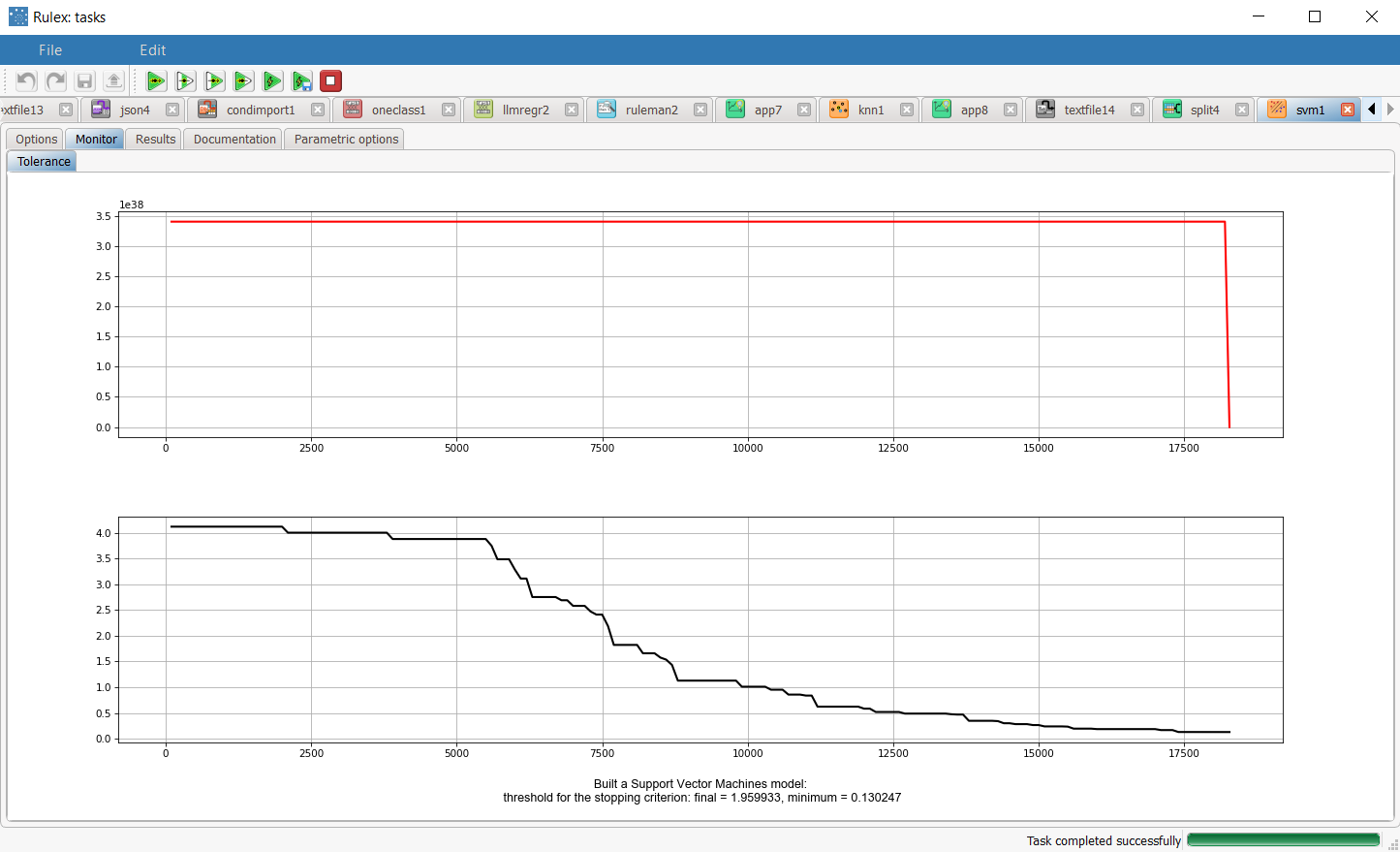 |
The forecast ability of the set of generated rules can be viewed by adding an Apply Model task to the SVM task, and computing with default options. |  |
The forecast produced by the Apply Model task can be analyzed by right-clicking the SVM task and selecting Take a look. In the data table the following columns relative to the results of SVM elaboration have been added:
|  |