Using K-Nearest Neighbor to Solve Classification Problems
The K-Nearest Neighbor (KNN) classifier task determines the output of a new example on the basis its nearest neighbors.
In particular, given an input vector x, the algorithm finds its k nearest neighbors and then assigns x to most represented class in this subset of examples.
The output of the task is a structure that can be employed by an Apply Model task to perform KNN forecasts on a set of examples.
Prerequisites
the required datasets have been imported into the process
the data used for the model has been well prepared, and includes a categorical output and a number of inputs.
a single unified dataset has been created by merging all the datasets imported into the process.
Additional tabs
The following additional tabs are provided:
Documentation tab where you can document your task,
Parametric options tab where you can configure process variables instead of fixed values. Parametric equivalents are expressed in italics in this page (PO).
Points & Results tabs, where you can see the output of the task computation. See Results table below.
Procedure
Drag and drop the K-Nearest Neighbor task onto the stage.
Connect a task, which contains the attributes from which you want to create the model, to the new task.
Double click the K-Nearest Neighbor task.
Configure the options described in the table below.
Save and compute the task.
K-Nearest Neighbor options | ||
Parameter Name | PO | Description |
|---|---|---|
Normalization of input variables | normtype | The type of normalization to use when treating ordered (discrete or continuous) variables. Possible methods are:
Every attribute can have its own value for this option, which can be set in the Data Manager task. These choices are preserved if Attribute is selected in the Normalization of input variables option; otherwise any selections made here overwrite previous selections made. |
Aggregate data before processing | aggregate | If selected, identical patterns are aggregated and considered as a single pattern during the training phase. |
Initialize random generator with seed | initrandom, iseed | If selected, a seed, which defines the starting point in the sequence, is used during random generation operations. Consequently using the same seed each time will make each execution reproducible. Otherwise, each execution of the same task (with same options) may produce dissimilar results due to different random numbers being generated in some phases of the process. |
Append results | append | If selected, the results of this computation are appended to the dataset, otherwise they replace the results of previous computations. |
Input attributes | inpnames | Drag and drop the input attributes you want to use to build the network. |
Output attributes | outnames | Drag and drop the output attributes you want to use to build the model. |



Results
The results of the K-Nearest Neighbor task can be viewed in two separate tabs:
The Points tab, where it is possible to view the points employed to perform the KNN classification. If no aggregation is performed and no attributes are ignored, this corresponds to the training set table. However, in many cases this table significantly differs from the training set and is therefore shown separately.
The Results tab, where statistics on the KNN computation are displayed, such as the execution time, number of points etc.
Example
The following examples are based on the Adult dataset.
Scenario data can be found in the Datasets folder in your Rulex installation.
The scenario aims to solve a simple classification problem based on ranges on income.
The following steps were performed:
First we import the adult dataset with an Import from Text File task.
Split the dataset into a test and training set with a Split Data task.
Generate the model from the dataset using the K-Nearest Neighbor task.
Apply the model to the dataset with an Apply Model task.
View the results of the forecast via the Take a look function.
Procedure | Screenshot |
|---|---|
After importing the adult dataset with the Import from Text File task, and selecting line 2 to define the types, split the dataset into test and training sets (30% test and 70% training) with the Split Data task. | 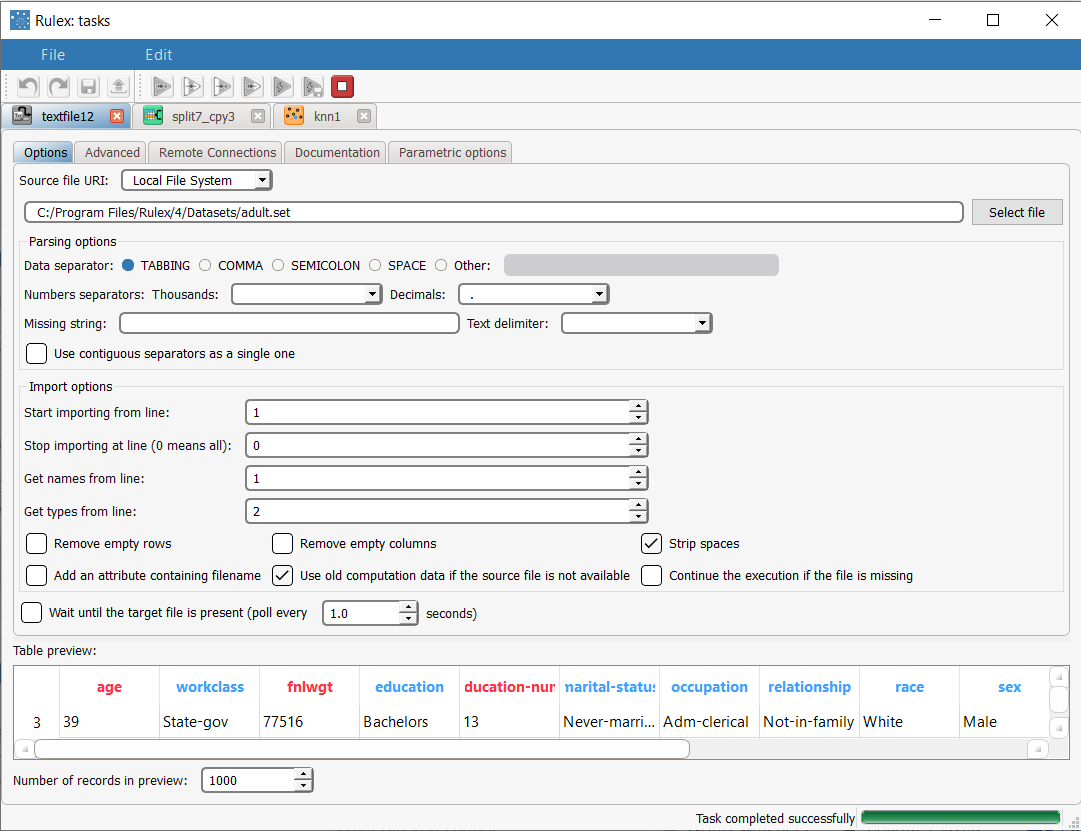 |
Add a K-Nearest Neighbor task to the process, drag and drop the Income attribute onto the Output Attributes edit box to define it as the output attribute, and drag and drop the following attributes as input attributes:
Leave the remaining settings as default, and save and compute the task to start the analysis. | 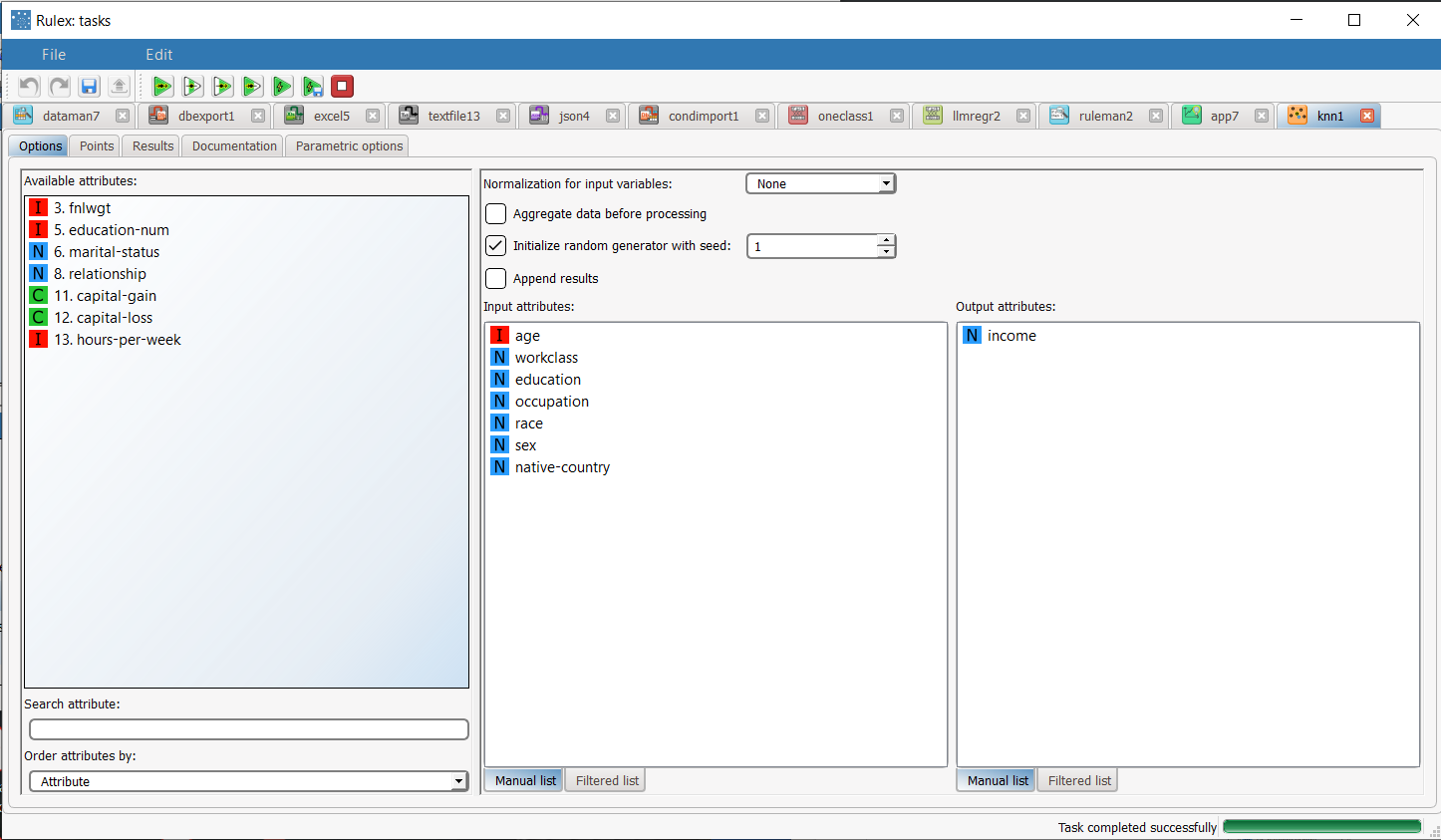 |
The Points table in K-Nearest Neighbor task contains the points (generated from the training set after an aggregation procedure) that will be used to perform the KNN classification. |  |
The forecast ability of the set of generated rules can be viewed by adding an Apply Model task to the K-Nearest Neighbor task, and computing with default options. In the Apply Model task it is possible to select the number of nearest neighbor points to be considered (i.e. the value of k): in this case we will select 5. | 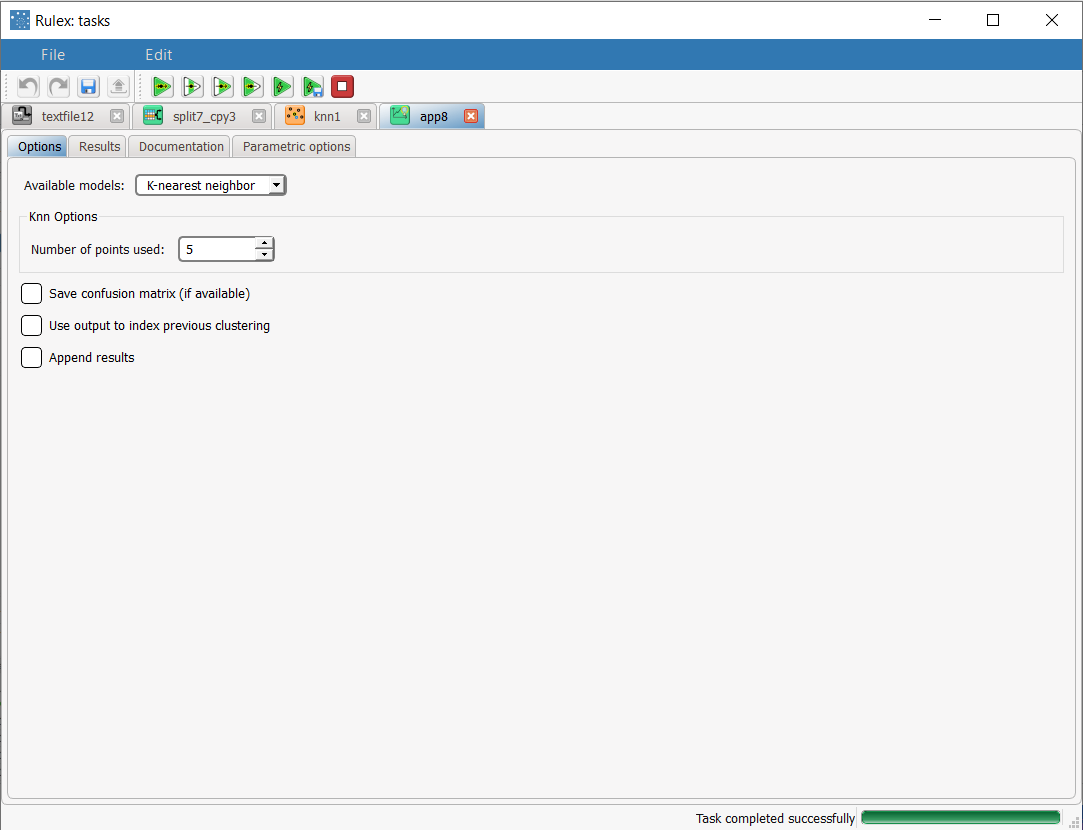 |
We can evaluate the accuracy of the model on the available examples by right-clicking the Apply Model task and selecting Take a look. The application of the rules generated by the KNN task has added new columns containing:
| 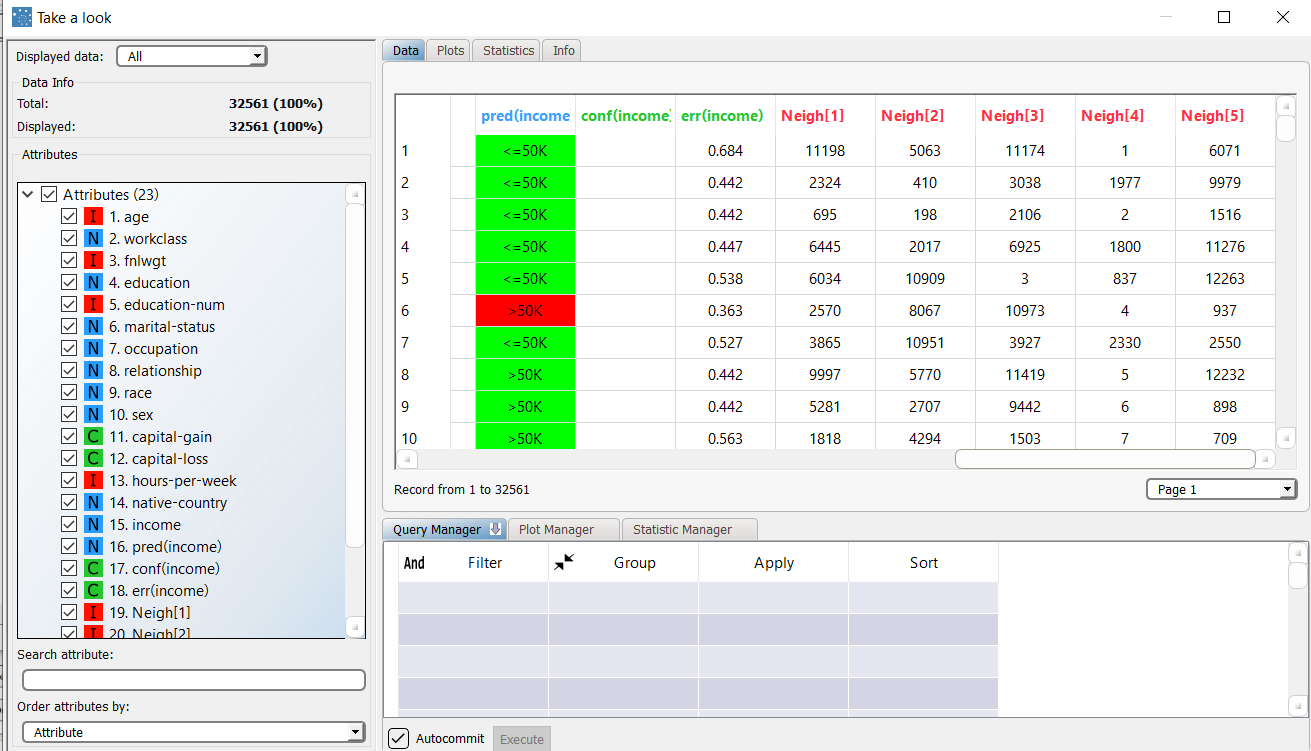 |