Datasets and Attributes
Datasets
Every process created in Rulex starts from one or more specific datasets, each of which contains the sample of observations for a system or a problem.
A dataset has a tabular form, where each row corresponds to an example (or pattern or record) and is composed of one or more elements (columns), called attributes (or variables).
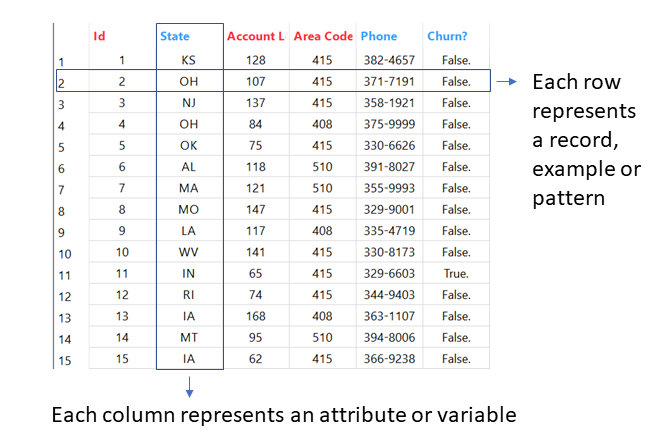
In Rulex an attribute is uniquely identified by its name and is defined in the following way:
it belongs to a type
it has a specific role
it may or may not be used in the final data analysis
Attribute types
Attribute type | Definition | Examples of valid attributes |
|---|---|---|
Nominal | An attribute with no intrinsic ordering | a color, the job of a person, a product code |
Integer | A positive or negative integer | the age of a person or the answer to a questionnaire |
Continuous | An intrinsically quantitative variable | the measurement of a physical quantity, the price of specific goods |
Date | A date in a valid format The date format summarizes in a single field 4 quantities:
| 1492/10/12, 12/10/1492, 1492-10-12, 12-10-1492, |
Time | A time in a valid format. The time resolution is milliseconds. | 17:27:35, 17:27:35.12, 5:27:35 PM, 17:27, 5:27 PM |
Datetime | A combined date and time in a valid format The datetime resolution is seconds. |
|
Month | A month in a valid format | 1492/10, 10/1492, 1492-10, 10-1492, 1492/Oct, 1492-Oct, Oct/1492 and Oct-1492. |
Week | A week in a valid format. International week numbering conventions are used, therefore | 1492/W41, W41/1492, 1492-W41, W41-1492 |
Quarter | A period of three months in a valid format Notice that:
| 1492/Q3, Q3/1492, 1492-Q3, Q3-1492 |
Any string of printable ASCII characters, not including backslashes ‘’ or double quotation marks ‘”’, can be used for the name of any item or for the value of any attribute. Strings are memorized and shown in their original form but are always treated in a case insensitive way; consequently Rulex considers “People”, “people”, and “PEOPLE” as the same string.
Only some statistical and machine learning algorithms, such as logic learning machines, and hierarchical basket analysis, are able to deal with nominal attributes; other operations transform nominal attributes into discrete attributes. Consequently a fictitious ordering is used for the values of those attributes that may affect the outcome of the results.
Attribute roles
Each attribute of the dataset may assume one of the following roles:
Role | Definition |
|---|---|
Input | An input variable in a supervised learning problem |
Output | A target variable of a supervised learning problem. |
Profile | The attribute to be employed to measure similarities in an unsupervised learning problem. |
Weight | The variable that provides a measure of relevance for each example in the dataset. |
Cluster Id | A nominal attribute containing the cluster assignment for each pattern in an unsupervised learning problem. This role can also be used to provide the clustering technique with an initial assignment chosen by the user. |
No Role | Variables that do not assume a specific role in the current analysis. |
Attributes used for data analysis
Attributes are also characterized by a Boolean property, which defines whether or not the attribute will be used in the data analysis:
Ignore: if true, the attribute is not considered in the analysis.
Label: if true, the attribute is considered as a unique identifier of the pattern. This tag is used by the label clustering and projection clustering tasks.
Some algorithms implemented in Rulex cannot manage missing values in the data table. For this reason each attribute is also characterized by a value for missing that replaces missing record in the dataset.