Transposing Data
Transposing datasets converts rows into columns and vice versa.
This conversion may be required to merge data tables prior to performing in-depth analyses.
Prerequisites
you have created a process in Rulex
the required datasets have been imported into the process.
Procedure
Drag and drop the Transpose task onto the stage.
Connect a task that contains the attributes you want to transform to the Transpose task.
Double click the Transpose task.
Select Put attribute names as first column (userow) to include attribute names as the first column in the transpose table. If not selected the attribute names will be removed in the resulting dataset.
Select Use first column as attribute names (usecol) to use the first column of the original dataset to determine the attribute names of the transpose table. If not selected generic names are employed.
Save and compute task.
Example
The following example is based on the Northwind dataset.
The scenario data can be found in the Datasets folder in your Rulex installation.
The original dataset consists of 77 rows (samples) with 10 variables (columns) with different data types.
Our aim is to convert the 77 rows to columns.
The following steps were performed:
First we import the northwind_products.set dataset.
Use the Take a Look functionality to visualize the training set prior to transformation.
A Transpose task is added to reshape the dataset.
Use the Take a Look functionality to visualize the training set after transformation.
Procedure | Screenshot |
|---|---|
After importing the northwind_products.set dataset with an Import from Text File task, right-click the task and select Take a look to visualize the imported data. The original dataset consists of 77 rows (samples) with 10 variables (columns) with different data types. There are 3 nominal attributes, while the remaining attributes are integers. | 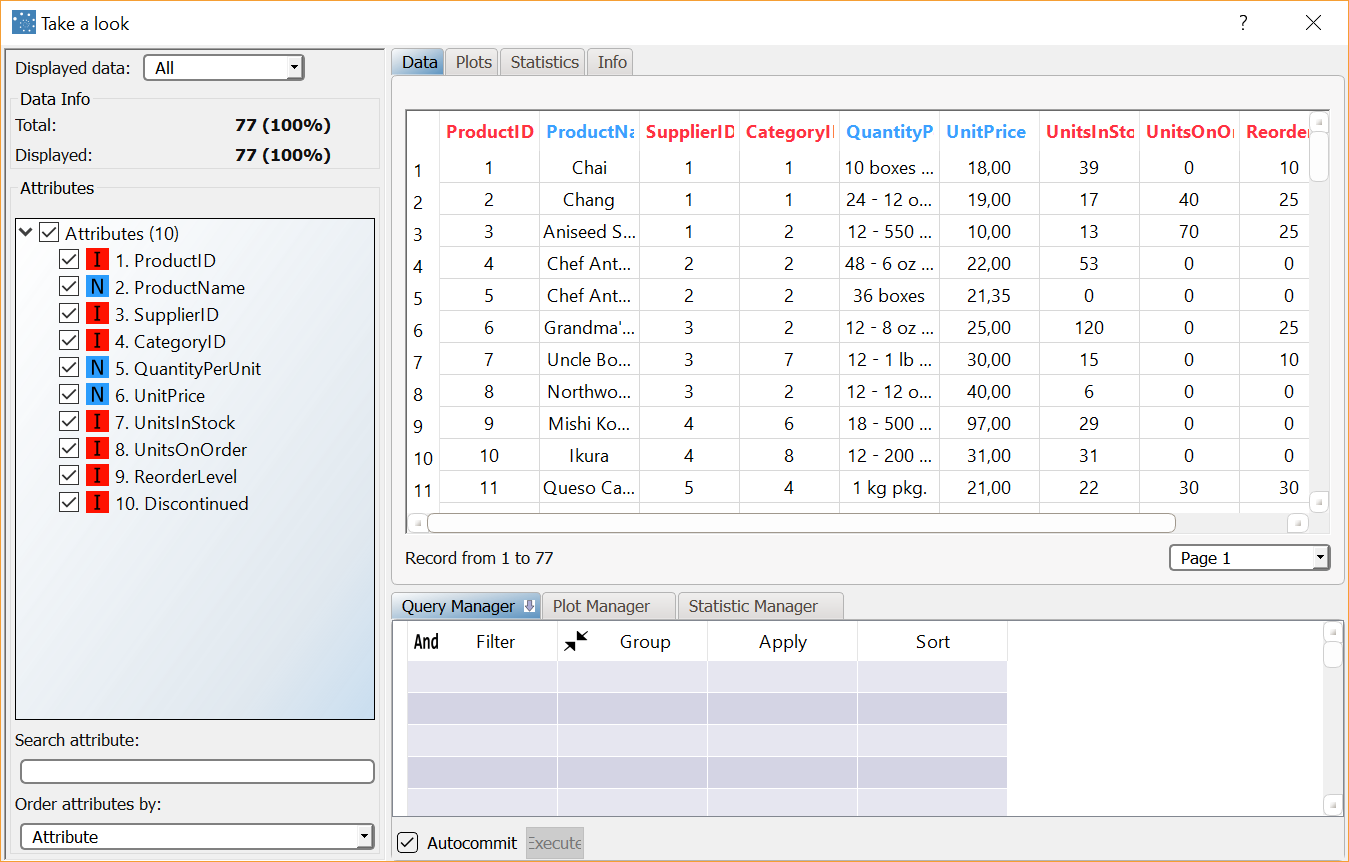 |
Add a Transpose task to the stage, and select both the Put attribute names as first column and Use first column as attribute names options (default value); then compute the task. | 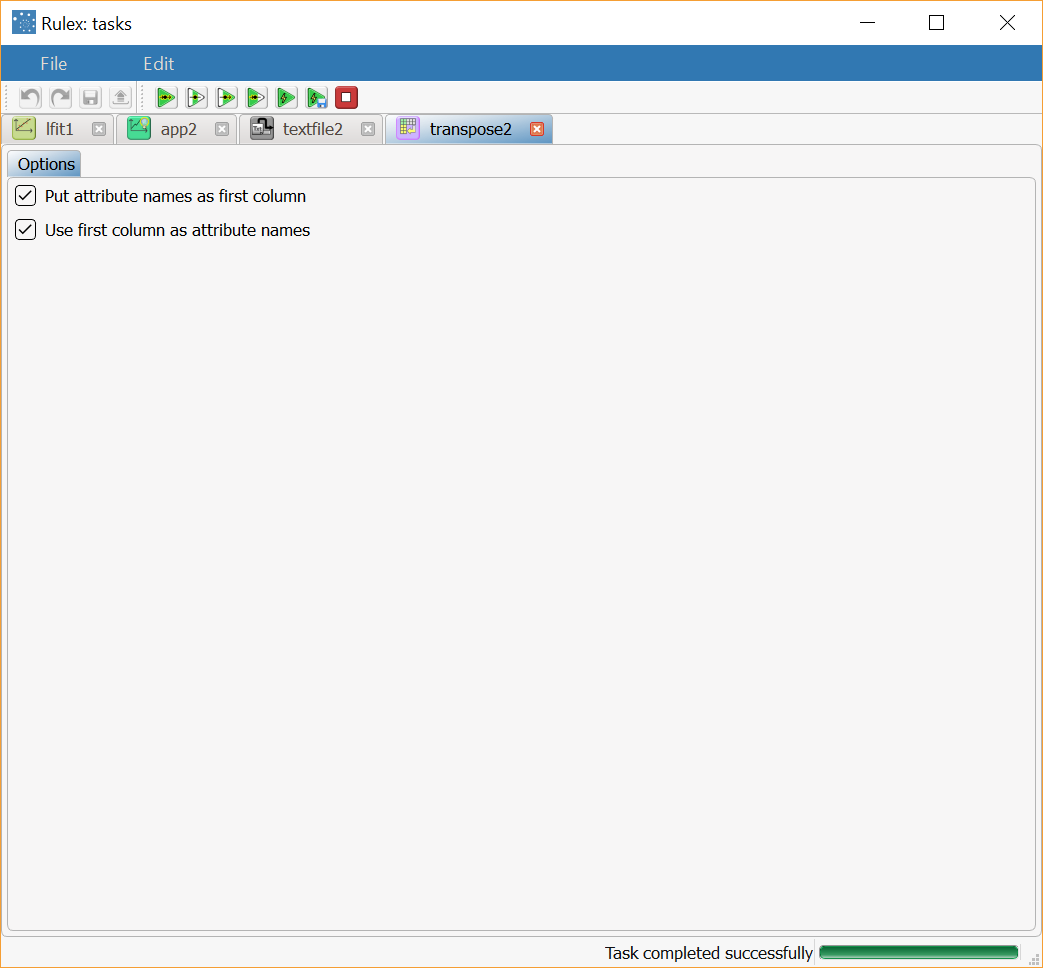 |
Right-click the task and select Take a look to visualize the results. The dataset now contains:
Note that all the attributes in the transposed dataset are nominal since only this is the only way to satisfy the constraint that all the elements in a column have the same type. | 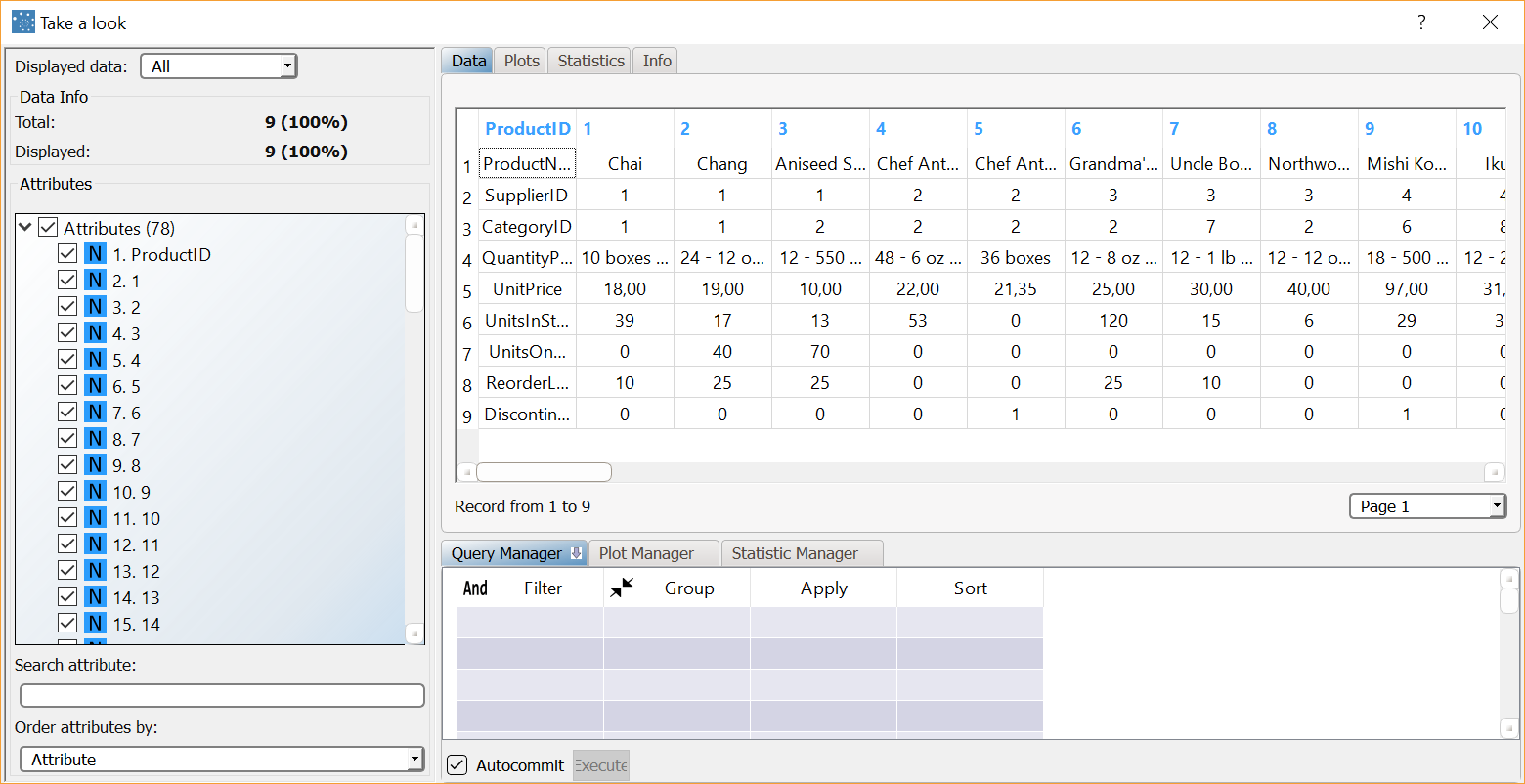 |