Reshaping Datasets to Wide Format
The reshape to wide pivoting operation reshapes a dataset by:
transforming a key attribute into a new set of attributes for each row
creating a new column for each distinct value of the transformed key attribute.
Consequently the number of keys in the dataset will be decreased, which is often a prerequisite for merging datasets.
Prerequisites
you have created a process in Rulex
the required datasets have been imported into the process.
Additional tabs
The following additional tabs are provided:
Documentation tab where you can document your task,
Parametric options tab where you can configure process variables instead of fixed values. Parametric equivalents are expressed in italics in this page (PO).
Procedure
Drag and drop the Reshape To Wide task onto the stage.
Connect a task that contains the attributes you want to transform to the Reshape To Wide task.
Double click the Reshape To Wide task. The left-hand pane displays a list of all the available attributes in the dataset, which can be ordered and searched as required. Select the attributes that will be displayed in the final table (othnames), by checking the corresponding box (by default all the attributes are included). Notice that, since the number of rows in decreased by the Reshape To Wide task, if you check an attribute without dragging and dropping it into the Widened attributes list, in the final table you will have only the value contained in the first line for each value of the Key Attributes.
Configure the task options as described in the table below.
Save and compute the task.
Reshape to Wide options | ||
Name | PO | Description |
|---|---|---|
Fill missing values | fillmiss | If selected, zeros will be inserted in every empty cell of the wide columns in the new reshaped table (empty cells in the final table correspond to the combinations of key/long attributes not present in the long dataset). |
Remove prefix from widened attribute name | nonames | If selected, the prefix "Value" is removed from widened attributes to avoid having the same initial attribute name repeated for every new column in the table. By default, the new columns are named Value(long_value) where long_vaue is a possible value for the long attribute. |
Key attributes | keynames | Drag and drop the attributes that will be used as a key to identify each group of records. A record/row will be created for each distinct set of values of the key attributes. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. |
Long attributes | longnames | Drag and drop the attributes that will be become column headers in the wide format. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. Note that the combination of Key attributes and Long attributes should be a unique key in the original table. If this is not the case, you have to group according to Key attributes and Long attributes in a Data Manager before applying Reshape To Wide. |
Widened attributes | widenames | Drag and drop the attributes that will become column values in the resulting data table. Instead of manually dragging and dropping attributes, they can be defined via a filtered list. |
Example
The following examples are based on the Adult dataset.
Scenario data can be found in the Datasets folder in your Rulex installation.
Our aim is to transform the dataset into a wide format, so that the resulting table will have a separate column for the number of hours worked per week, in each native country, according to the work class.
The following steps were performed:
First we import the adult dataset.
Then a Data Manager task is connected to the source block to visualize the training set, and prepare the data for reshaping.
A Reshape To Wide task is added to reshape the dataset.
Then we use the Take a look functionality to visualize data after transformation.
Procedure | Screenshot |
|---|---|
After importing the adult.set dataset with an Import from Text File task, add a Data Manager task to visualize the imported data. The original dataset is made up of 32561 records, with separate columns for the work class and the number of hours worked per week. Take a look vs Data Manager Here we will use a Data Manager and not the quicker Take a look functionality as we need to make changes to the dataset, and Take a look is read-only. |  |
To reshape the dataset we need to:
| 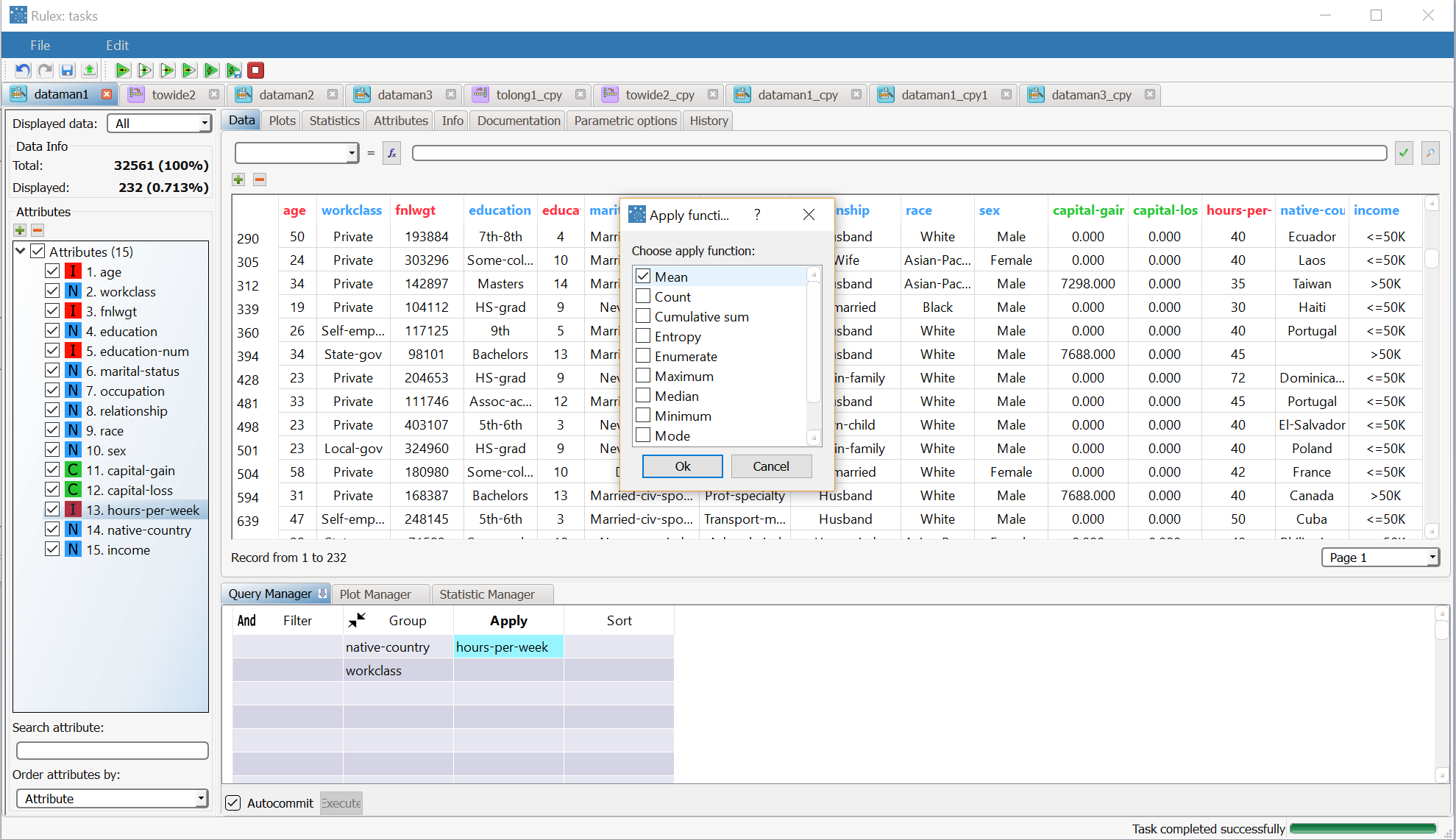 |
Now add a Reshape to Wide task to the stage and connect the previous Data Manager. In the attribute list on the left, select the attributes you want to include in the final dataset. Attributes added to the transformation edit box on the right are automatically included in the final data table. In the example, we have decided to display only the transformed attributes. Then drag and drop:
| 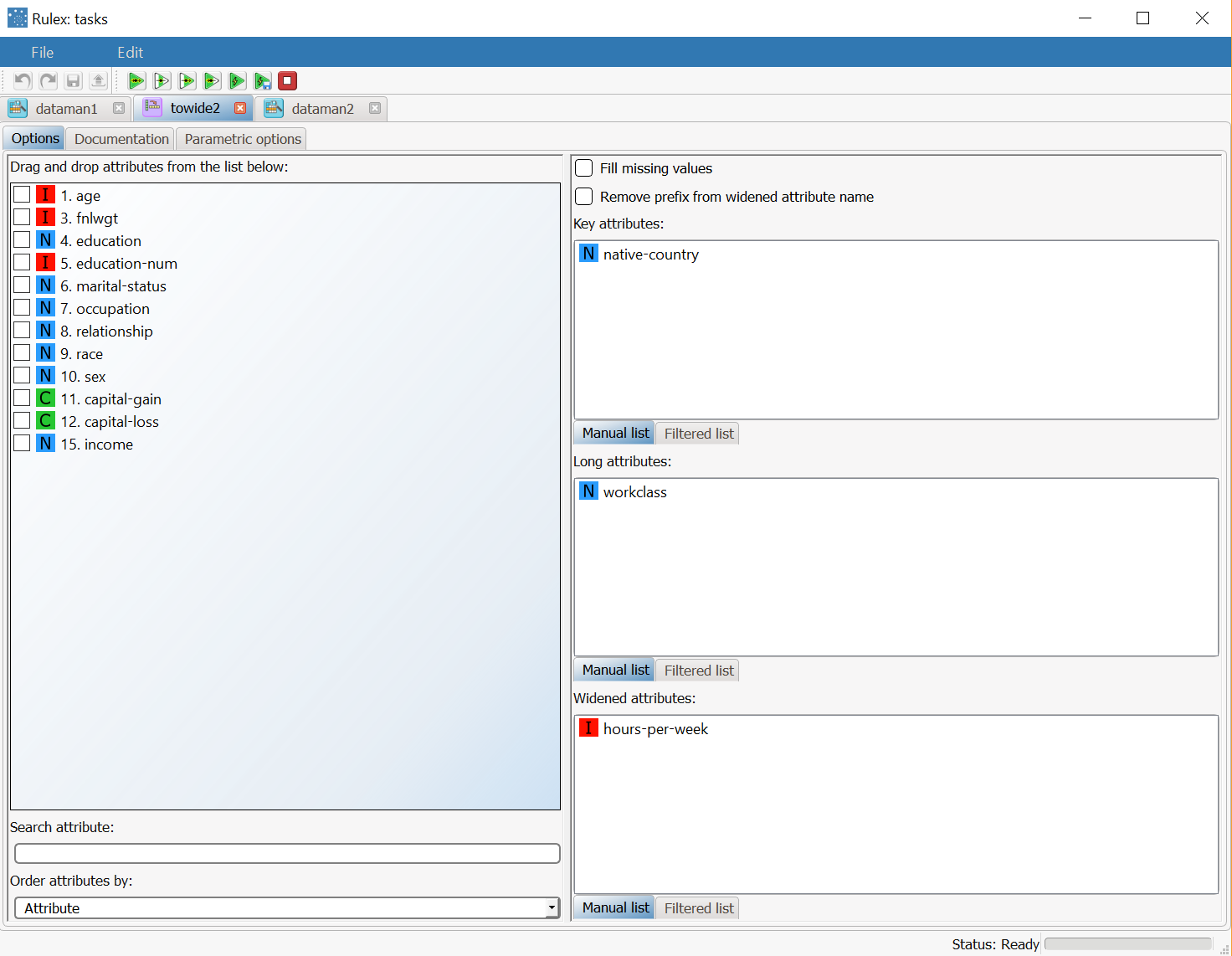 |
After computing the Reshape to Wide task, right-click it and select Take a look to view the resulting data. The new dataset contains 42 records, one for each native country. The number of attributes has increased and now includes a new column for each workclass, with its corresponding average number of hours worked for the relative native country. | 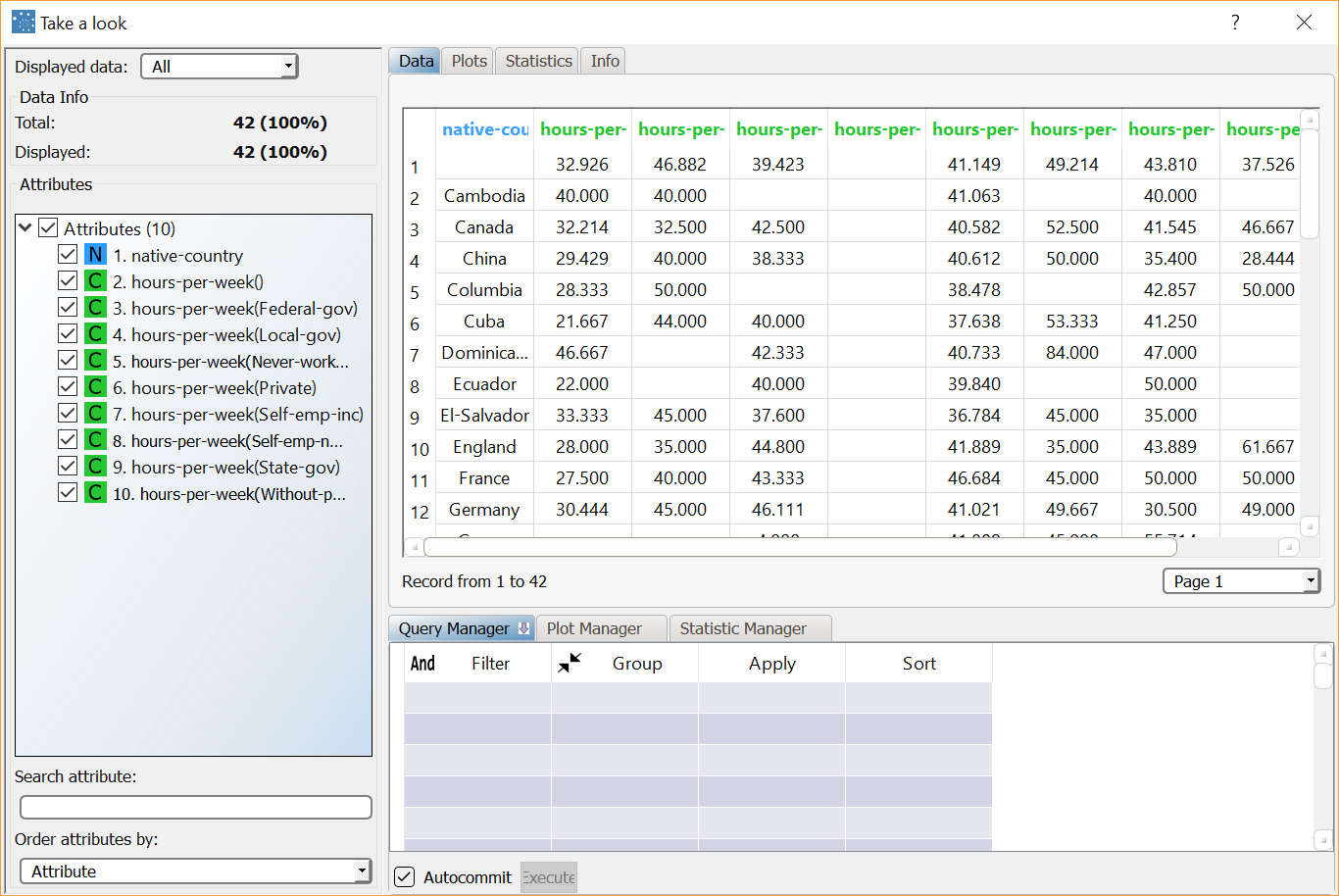 |