Discretizing Data
Discretization transforms continuous data by defining a set of cutoffs that subdivide a continuous domain into a finite set of homogeneous intervals.
The points in each interval should have a high probability of belonging to the same class. These intervals increase the effectiveness of data in the creation of predictive models.
Prerequisites
you have created a process in Rulex
the required datasets have been imported into the process.
Additional tabs
The following additional tabs are provided:
Documentation tab where you can document your task,
Parametric options tab where you can configure process variables instead of fixed values. Parametric equivalents are expressed in italics in this page (PO).
Procedure
Drag and drop the Discretize task onto the stage.
Connect a task that contains the attributes you want to transform to the Discretize task.
Double click the Discretize task. On the left hand side of the pane there is a list of all the available attributes in the dataset, which can be ordered and searched as required.
Configure the options, as described in the table below.
Save and compute the task
Discretize options | ||
Name | PO | Description |
|---|---|---|
Use previous cutoffs to discretize data | useprevious | If selected, the cutoffs defined in an upstream Discretize task will be used to discretize the new data, instead of defining new cutoffs. This is useful when you want data to be discretized in the same way in various point of the worklflow. |
Method for discretization | inpdisctype | Select the method you want to use from the Method for discretization drop-down list. Possible values are:
The Attribute Driven Incremental Discretization method usually scores the best performance but may be quite time consuming when there are large training sets. The Entropy method is usually faster but may generate some ambiguities and then compromise the accuracy of any subsequent analysis. |
Minimum distance between different classes | minwidth | Specifies the minimum distance that must be kept between two patterns of different classes, as the percentage of the total number of attributes. This distance is computed as the number of attributes whose values are different in the two patterns. The minimum and default distance is one. If you select 100% all the attributes of each couple of heterogeneous patterns must differ. This is not always possible since many attribute can have the same value in the starting data, and in this case the method uses the available separations. |
Number of patterns used for discretization | numdisc | Specifies how many patterns will be used. This option allows you to use only a randomly selected subset of the training set, which is particularly useful when there is a high amount of data, as a high number of patterns considerably slows sown the discretization process. The default value of -1 means that all patterns will be used. |
Number of values for ordered variables | ninpval | Specifies the number of cutoffs to be inserted for each variable, which must not exceed the number of values available in the training set. The number of cutoffs must at least ensure that the minimum distance between different classes can be guaranteed. |
Preselect best cutoffs | preselcut | If selected, the most promising cutoffs will be selected and employed in the subsequent phase. This consequently reduces the number of possible cutoffs to be analyzed. This works particularly well coupled with the Attribute Driven Incremental Discretization method. |
Aggregate data before processing | aggregate | If selected, identical patterns will be aggregated and considered as a single pattern during the discretization phase. |
Output attribute | outdiscname | Select the output attribute to be used for discretization from the drop-down list. Output attributes are mandatory for supervised methods. |
Discretize output | outdisc | If selected the output attribute will be discretized. This option is available if you selected a discrete (e.g. integer) or continuous output attribute. You can then select the required discretization method in the Discretization method for output option.
|
Discretization method for output | outdisctype | Select the discretization method you want to adopt to discretize the output. This option is available only if you have selected the Discretion output option. Possible methods are:
|
Number of cutoffs for output | noutval | Select the number of intervals to be created when discretizing output values. The default is 10 whereas 0 means that all possible cutoffs have to be inserted. This option is available only if you have selected the Discretize output option. |
Attributes to discretize | discnames | Drag and drop the ordered attribute you want to transform from the Available attributes list |
Results
The results of the Discretize task can be viewed in two separate tabs.
Monitor: this tab displays the distribution of the number of generated cutoffs in the form of a histograms during the execution of the Discretize operation. These plots are available also at the end of the computation.
Results: this tab displays summary information on the performed computation, such as the execution time, number of cutoffs etc.
Example
The following examples are based on the Adult dataset.
Scenario data can be found in the Datasets folder in your Rulex installation.
In the example process discretization is performed on data deriving from the source as follows:
The following steps were performed:
First we import the dataset.
Use the Take a Look functionality to visualize the original dataset.
A Discretize task to define cutoffs.
Use the Take a Look functionality to visualize data after discretization.
Procedure | Screenshot |
|---|---|
After importing the adult.set dataset with an Import from Text File task, right-click the task and select Take a look to visualize the imported data. The original dataset is made up of 32561 records, and the age attribute includes almost all the possible integer values between 17 band 90. We want to group all these possible values into 5 groups of equal frequency. | 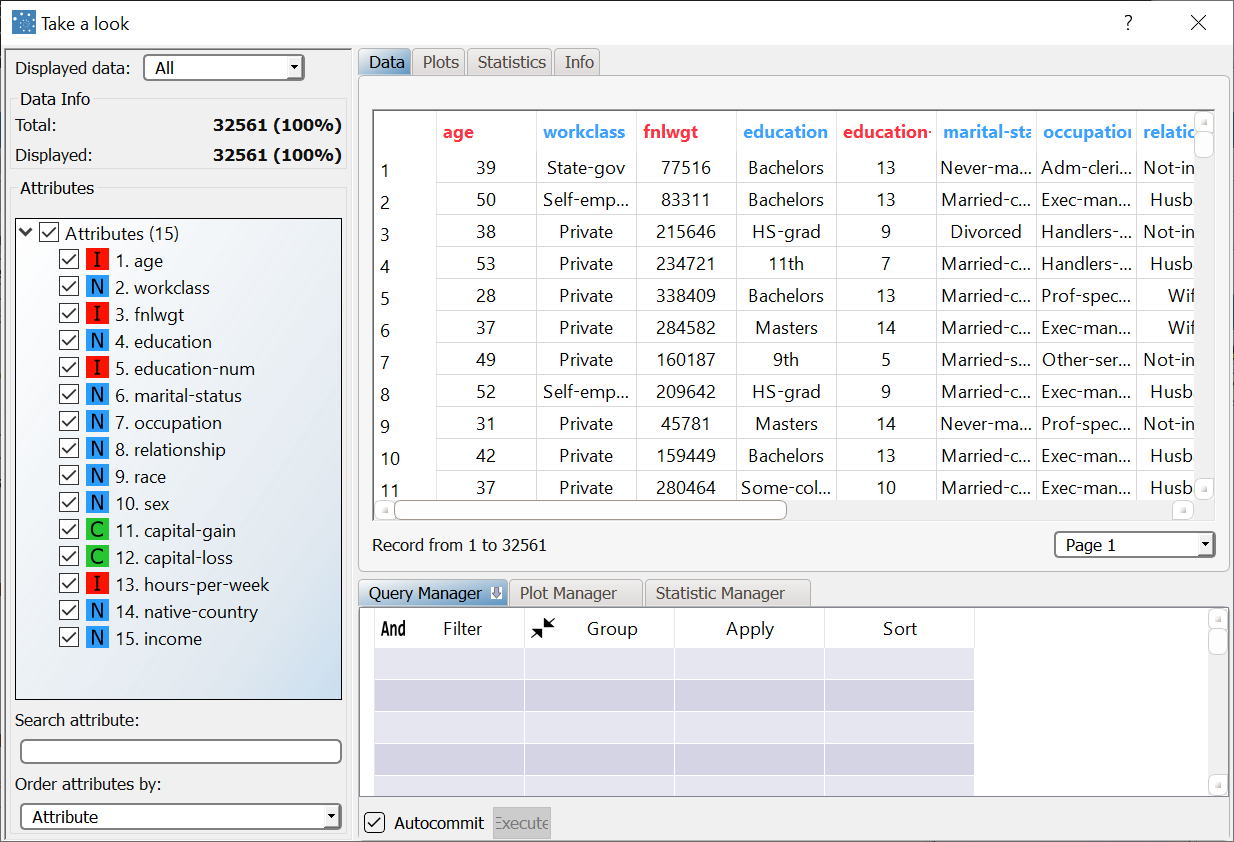 |
Add a Discretize task to the process and specify the following:
| 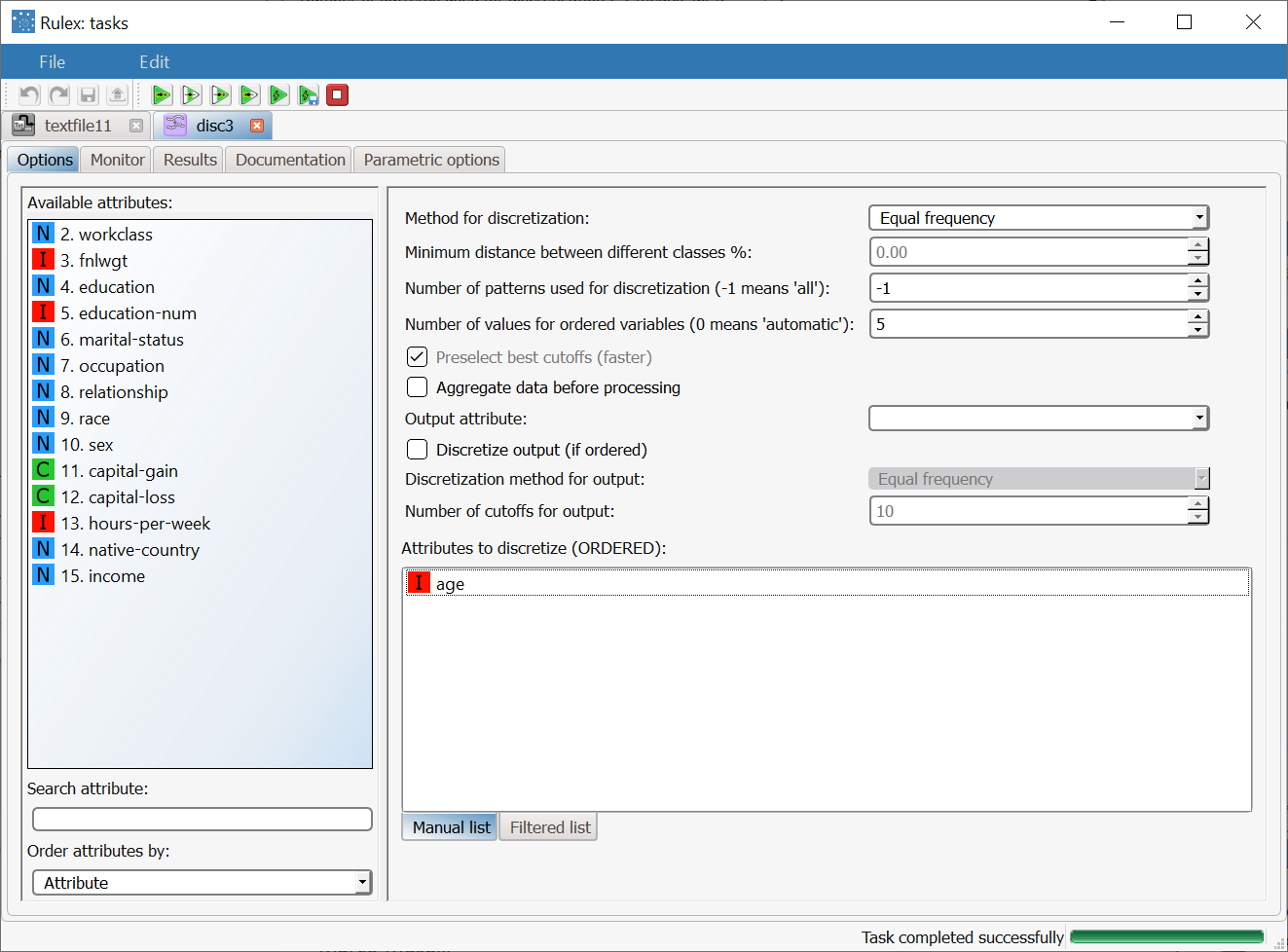 |
After running discretization the Monitor tab displays a histogram which reports the distribution of the number of cutoffs for each variable. The Results tab summarizes information on the computation just performed. | 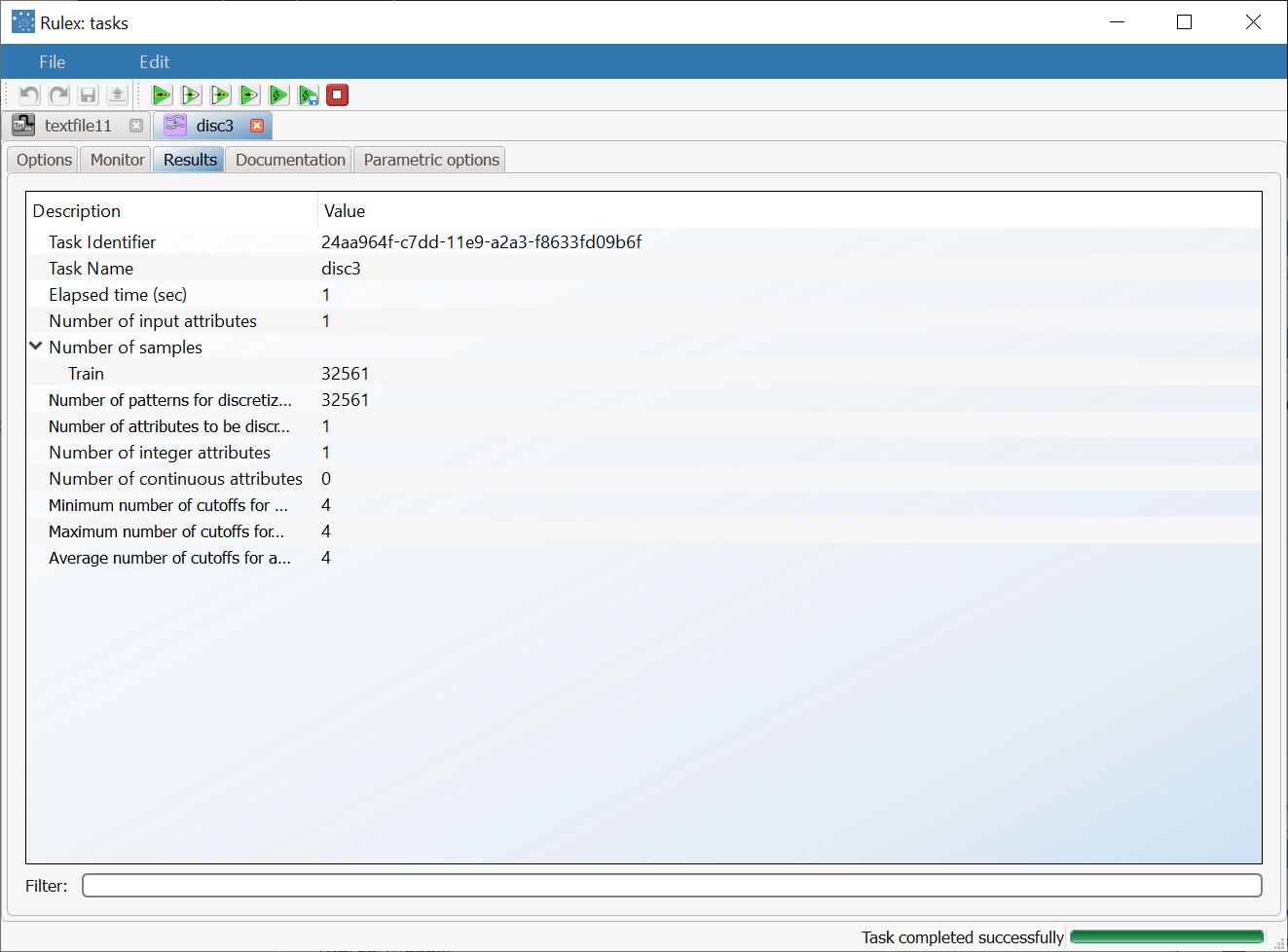 |
Right-click the Discretize task and select Take a look to check the results. You can see straight away that the age values have been grouped, as there are a fewer number of possible values. | 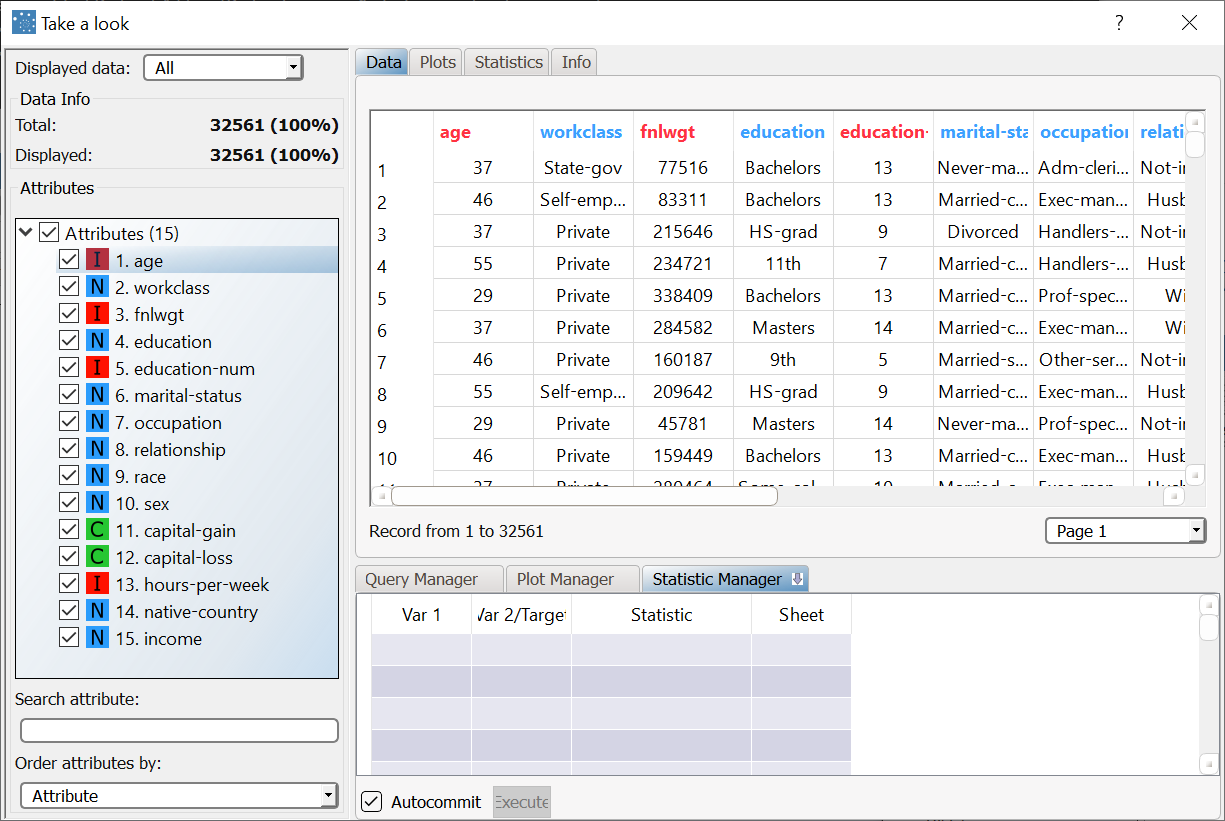 |
To examine how the discretize task has grouped values in more detail, drag and drop the age attribute onto the Var1 column of the Statistic Manager, and select Values, frequencies and quantiles as the type of statistics. Here you can see the five groups that have been created, with their assigned average values, and the number of rows belonging to each group. | 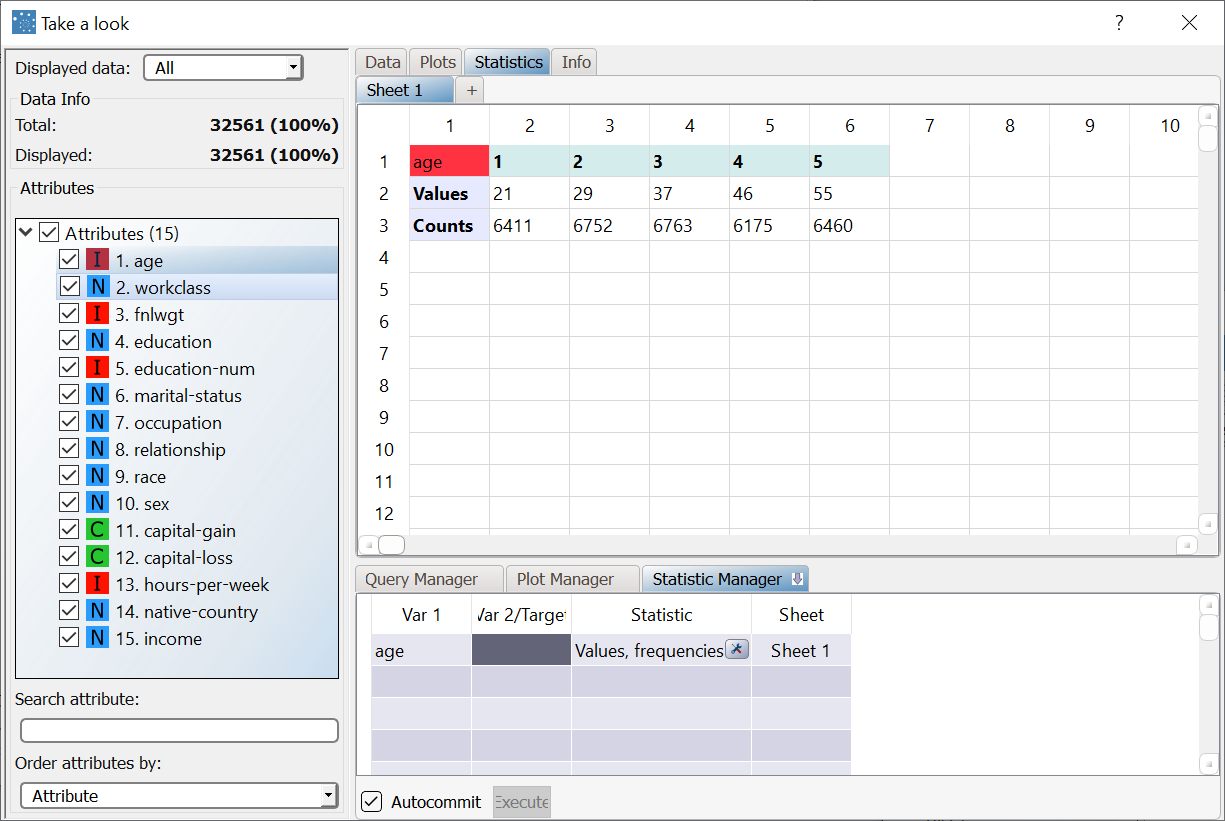 |