Managing Attribute Properties
Attribute properties can be easily modified in the Data Manager inside the Attributes tab.
The Info tab displays read-only global information on all attributes in the data set, divided into the following categories:
General, displaying the total number of current attributes, attributes from previous computational tasks, ignored attributes and label attributes
Types, displaying the total number of attributes by attribute type
Roles, displaying the total number of attributes by attribute role.
You can change the following properties of the attribute you have selected in the Attributes list:
Property name | Description |
|---|---|
Name | Enter a unique identifier for the attribute. |
Type | Change the attribute type. Note that an incorrect data type may have been incorrectly assigned automatically during the data import operation, due to one or more values having been inserted with the incorrect format. If you try to change the data type to the correct type, Rulex will tell you which row contains the format error. For possible attribute types and their meanings see Datasets and Attributes. |
Role | Change the role of the attribute. For possible attribute roles and their meanings see Datasets and Attributes. |
Ignore | If selected, the attribute is not considered in modeling operations. |
Label | If selected, the attribute is considered as a unique identifier of the pattern, and rows are first grouped according to their labels and then processed. Consequently each label combination corresponds to a row in the dataset. This function is used by only some advanced clustering tasks, and should generally be left unchecked by default. |
Use position to locate the attribute | If selected, the attribute is located by its position and not by its name. When the property of an attribute is modified, such as its role or type, the name of the attribute is normally used as a reference. If the operation is copied and pasted into another Data Manager, the operation will be performed on the attribute with the same name (if there is one). If this option is checked the operation will be performed on the attribute which is in the same position in the dataset. |
Values | The possible values for the selected attribute are displayed. No values are displayed for ordered variables. |
Missing management - value for missing | The value that should be inserted if a task requires a value and no value is present. If no value is entered here the default value is used, i.e. the average for ordered attributes and the mode for nominal attributes. This is necessary, as some algorithms implemented in Rulex cannot manage missing values in the dataset. Clicking Impute fills all the empty cells with the specified value. |
Normalization | Select the method you want to use to normalize variables. Possible methods are:
|
Distance | Select the method you want to use to compute the distance between two patterns as regards the select attribute. The distance between two examples is computed as the combination of the distances for each attribute. Possible choices are: Euclidean, Euclidean (normalized), Manhattan, Manhattan (normalized) and Pearson. Suppose that there are nE attributes for which Euclidean is to be used (normalized or not), nM attributes for which Manhattan distance is to be used (normalized or not) and nP attributes for which the Pearson distance is to be used. Let's denote with xE, xM, xP the subsets of x containing the values associated with the attributes where Euclidean, Manhattan and Pearson distance is to be used, respectively. If the normalized distance is to be used, suppose that the values in xE, xM, are already normalized (see the section on Normalization for further details). Then the distance between two patterns x and y can be defined as: 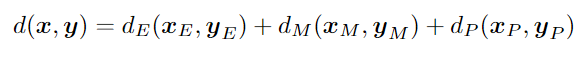 Where the distances are defined as follows: 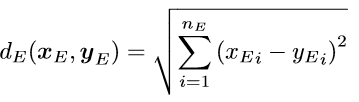 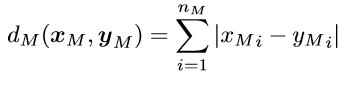 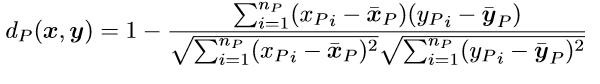 Where:
|
Minimum, Maximum, Average and Standard Deviation | Specify values used in the above formulas:
In the formulas regarding distance and normalization the average, standard deviation etc. are computed on the training set, but if required different values can be specified here. |


