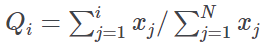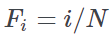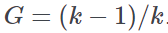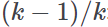Computing Statistics - Single Statistics
Single statistics are statistical functions used to perform preliminary descriptive analyses.
They are univariate statistics.
Properties
Properties | Description |
|---|---|
General parameters | |
Statistics on integer variables are continuous | If selected, statistics will be displayed as continuous values (e.g. 12,34 instead of a rounded off 12). |
Sample size | |
Number of total valid samples | Number of rows with valid values, not including missing values. |
Concentration measures | |
Gini concentration index | Computes the Gini concentration index, which is obtained from the following equation: 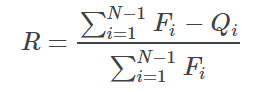 where:
|
Dispersion and heterogeneity measures | |
Number of mode elements | Shows the number of cases where the value corresponds to the mode. In a statistical distribution the mode represents the most frequently observed value, and the number of mode elements corresponds to the number of occurrences of tied values. |
Entropy | A heterogeneity measure, which is obtained, for a categorical variable, from the following equation: 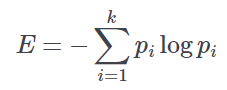 where:
|
Normalized entropy | Value obtained by dividing the entropy value by its maximum theoretical value (i.e. log(n)). |
Gini coefficient | Coefficient commonly applied to qualitative ordinal variables to evaluate the dispersion of values across different categories. It is estimated by the following equation: 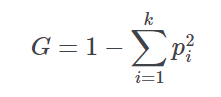 where:
G takes the minimum value of zero when there is only one category (maximum concentration), while if there is only one value in each stratum (maximum dispersion) |
Normalized Gini coefficient | Coefficient with the same meaning as the non-normalized statistic, but it is forced to vary between 0 and 1, simply dividing the G value by its maximum theoretical value 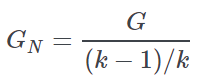 |
Range of values | The difference between the highest and the lowest values observed for the attribute X. |
Interquartile range | A dispersion measure often applied to continuous variables when their distribution is non Gaussian. It represents the difference between the 75th and the 25th percentile, corresponding to the 75% and the 25% value of the cumulative distribution of X, respectively. |
Standard error of mean | A dispersion measure usually used to evaluate the precision of a mean estimate. It is obtained by the ratio between the standard deviation and the square root of the number of subjects under study. |
Standard deviation | The square root of the variance (defined below). It is often used instead of the Variance as it has the same unit of measure as X. |
Standard error of standard deviation | Provides a measure of the uncertainty of the Standard deviation estimate. It is seldom used. |
Variance | It is among the most commonly used dispersion measures. It is estimated by the following equation (sample variance): 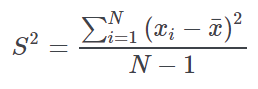 |
Standard error of variance | A measure of the precision of the variance estimate. It is seldom used. |
Coefficient of variation | The ratio between the standard error and the mean of an observed distribution. It represents a dimensionless measure of dispersion and it should be calculated only for continuous attributes, which take positive values. |
Mean absolute deviation | The mean of the absolute values of the difference between each value and the average of the attribute X. It is seldom used in favor of the Variance measure as it has better statistical properties. |
Median absolute deviation | The median value of the absolute values of the difference between each value and the average of the attribute X. It is a very rarely used as a measure of dispersion. |
Descriptive, location and central tendency measures | |
Number of distinct values | The number of non coincident (tied) values. |
Number of missing values | The number of missing values. |
Mean value | The simple arithmetic (unweighted) mean of the observed X values: 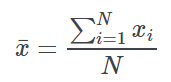 |
Absolute mean value | The mean value obtained from the absolute value of each observation. |
Geometric mean value | A central tendency measure that should be calculated for positive values only: 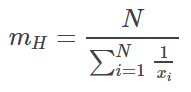 It is often applied to evaluate the average mean time needed to perform a specific task or as a measure of average speed. |
Geometric absolute mean value | The geometric mean value obtained from the absolute value of each observation. It is seldom used. |
Harmonic mean value | The harmonic mean value obtained from the value of each observation. |
Harmonic absolute mean value | The harmonic mean value obtained from the absolute value of each observation. It is seldom used. |
Median value | The value that makes it possible to split the X distribution into two equally sized samples (or almost equally sized, in the presence of an odd number of distinct values), corresponding respectively to the values ≤ median and > median. If there is an odd number of distinct X values, the median belongs to the X observed distribution. For example, if there are 5 valid items of data, the third ordered value corresponds to the median. Otherwise the median value is estimated by a simple interpolation, for example if there are 6 distinct values, the average between the 3rd and the 4th ordered value is used. |
Mode value | The most frequent observation. |
Index of the mode element | The position of the most frequently observed value in the original (unsorted) X attribute. |
Minimum value | The valid lowest value observed. |
Index of the minimum element | The position of the lowest observed value in the original (unsorted) X attribute. |
Maximum value | The valid highest value observed. |
Index of the maximum element | The position of the highest observed value in the original (unsorted) X attribute. |
Sum value | The sum of all valid observations. |
Absolute sum value | The sum of the absolute value of each observation. |
Product value | The product of all valid observations. |
Absolute product value | The absolute value of the product between each observed value. |
Lower quartile | The value that separates the quarter of ordered data with the lowest values from the 75% of the remaining observations. It is also called “the 25th percentile” and is used together with the upper quartile and the median value to obtain a box plot. For further information on boxplots see Plotting Data - Box Plots. |
Upper quartile | The value that separates the quarter of ordered data with the highest values from the 75% of the remaining observations. It is also called “the 75th percentile” and is used together with the lower quartile and the median value to obtain a box plot. |
Lower whisker for boxplot | The value corresponding to three times the standard deviation below the mean. It is used as a threshold to detect outliers detection and is part of the box plot. |
Upper whisker for boxplot | The value corresponding to three times the standard deviation above the mean. It is used as a threshold to detect outliers and is part of the box plot. |
Symmetry and shape measures | |
Skewness value | A measure of asymmetry. Symmetric distributions have zero skewness, whereas positive values are associated with right asymmetry. It is obtained by the following equation: 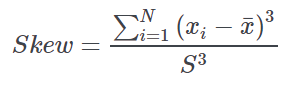 |
Standard error of skewness | An estimate of the precision of the skewness value estimate. |
Kustosis value | A measure of how data are peaked. For example, kurtosis of a standard Gaussian distribution is 3.0. Distribution with a higher kurtosis is said to be leptokurtic while distributions with a lower value are called platykurtic. The Kurtosis value is obtained by the following equation: 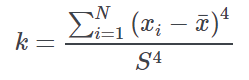 |
Standard error of kurtosis | A measure of the precision of the Kurtosis estimate. |