What's New in Rulex 4.2
New Features in Rulex 4.2 Feature Description Import from R and RBridge Tasks NEW New Python Import Bridge and Python Bridge tasks have been introduced in Rulex 4.2 to facilitate communication with Python scripts. The R Import Bridge and R Bridge tasks previously present in Rulex 3.2 have also been reintroduced, but with an improved performance of the external language connectors compared to the previous version. For further information Check out the following topic in the Rulex Process Development Manual Using External Scripts in Rulex Import from Cloudera Impala, Apache Spark, Teradata and Gupta SQLBase DB NEW Cloudera Impala, Apache Spark, Teradata and Gupta SQLBase DB have been added to the list of possible database distributions which can be used in database import and export operations. For further information Check out the following topics in the Rulex Process Development Manual: Conditionally Importing Data from Databases Database Settings Workflow Versioning NEW In previous versions of Rulex you could either duplicate your process every time you wanted to fix a version, or export the process with its date and time as a suffix. To avoid the human errors inherent in manual activities, and to minimize memory occupation, processes can now be versioned directly from the Rulex interface. This first release of Rulex versioning allows you to save, update, merge and retrieve specific versions of a process, tag specific versions and revert to previous versions. The versioning system is based on the Git version control system. For further information Check out the following topic in the Rulex Process Development Manual Versioning Processes and watch the YouTube video on Rulex versioning Search AssistantNEW A search feature is now available in Rulex, which allows you to search for a particular word or process variable within different processes. The search function shows all occurrences of the searched word in the options, histories and task definitions. Changes can also be applied to all occurrences from a central point. Another frequent problem that can occur is when you want to delete a process variable, but are unable to do so because it is in use. Thanks to the search function you can check which tasks use it and decide whether it can effectively be removed, and how. For further information Check out the following topic in the Rulex Process Development Manual Searching Tasks Conditional Import from DB NEW A new task, called Conditional Import from DB, has been introduced, which performs an import from a database conditioned by a set of constraints defined through a dataset (each row is a constraint) or a set of rules in if-then form. For further information Check out the following topic in the Rulex Process Development Manual Conditionally Importing Data from Databases Workflow execution parameters - priority policy NEW Two ways of managing priorities have been added to the Process Execution Parameter pane. These two options help solve ambiguous situations, where either the parent relationship or priority level are considered more important. See example below. For further information Check out the following topic in the Rulex Process Development Manual Modifying Process Execution Model to dataset new conversion tasks NEW Two new tasks have been added to Rulex to make it possible import and export models to file and database: The Convert Model to Dataset task produces a dataset that contains all the information included in the model, which can then be visualized in a Data Manager or exported to an external item, such as a file or database table. The Convert Dataset to Model task takes a dataset with a proper format and outputs the corresponding model, which can then be used in an Apply Model task in order to derive responses for specific samples. Priority policy example Consider the following process: If parent first is selected as the priority policy, the tasks will be computed according to their priority level, respecting the hierarchy of the process tasks. Consequently: ImportC (as it has the highest priority among the parent tasks: 3) Import B (priority 2) ImportA (priority 1) Concat Data Manager (priority 10, but it cannot be computed before its parent tasks) If priority first in selected as the priority policy, the highest priority becomes the Data Manager, despite its hierarchical position. Consequently all the tasks required to compute the Data Manager are assigned its same priority. So ImportA, ImportB, and Concat all assume priority 10, and the computation order consequently becomes: ImportA and ImportB are executed in parallel Concat Data Manager ImportC (whose priority of 3 is now the lowest priority in the process). Change Description New ODBC library to deal with DB CHANGE The library used to connect Rulex to the working and external database has been changed in the kernel from SQLAPI++ to ODBC. The ODBC library represents the world standard as regards DB connections, used by most commercial and open source software for DB access. For further information Revision of all the http/cloud remote connectors CHANGE All the http/cloud connectors (http/ftp/sharepoint/s3/hdfs) have been rewritten to increase their stability and speed. For example, the SharePoint connector is now twice as fast and the S3 connector three times faster than in Rulex 4.1. Bulk import from excel, text file, json via remote connections CHANGE The bulk import feature has been extended to include import operations performed from remote connections. A new dialog box has been added from which you can select the multiple files and folders from which you want to import data. Usability improvements made to some Rulex tasks CHANGE The following tasks have been modified to improve usability: K-Nearest Neighbor K-Nearest Neighbor Regression LLM One-Class Classification SVM Regression SVM For further information Check out the following topics in the Rulex Process Development Manual: K-Nearest Neighbor K-Nearest Neighbor Regression LLM One-Class Classification SVM Regression SVM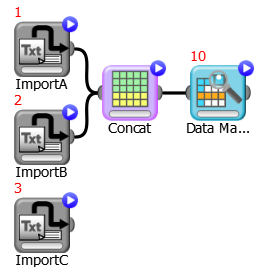
Changes made in Rulex 4.2